These are some notes I wrote a couple of years ago on Judith Grabiner’s paper ‘Is Mathematical Truth Time Dependent?’ David Chapman suggested I put them up somewhere public, so here they are with a few tweaks and comments. They’re still notes, though – don’t expect proper sentences everywhere! I’m not personally hugely interested in the framing question about mathematical truth, but I really enjoyed the main part of the paper, which compares the ‘if it works, do it’ culture of eighteenth century mathematics to the focus on rigour that came later.
I haven’t read all that much history of mathematics, so I don’t have a lot of context to put this in. If something looks off or oversimplified let me know.
I found this essay in an anthology called New Directions in the Philosophy of Mathematics, edited by Thomas Tymoczko. I picked this book up more or less by luck when I was a PhD student and a professor was having a clearout, and I didn’t have high hopes – nothing I’d previously read about philosophy of mathematics had made much sense to me. Platonism, logicism, formalism and the rest all seemed equally bad, and I wasn’t too interested in formal logic and foundations. However, this book promised something different:
The origin of this book was a seminar in the philosophpy of mathematics held at Smith College during the summer of 1979. An informal group of mathematicians, philosophers and logicians met regularly to discuss common concerns about the nature of mathematics. Our meetings were alternately frustrating and stimulating. We were frustrated by the inablility of traditional philosophical formulations to articulate the actual experience of mathematicians. We did not want yet another restatement of the merits and vicissitudes of the various foundational programs – platonism, logicism, formalism and intuitionism. However, we were also frustrated by the difficulty of articulating a viable alternative to foundationalism, a new approach that would speak to mathematicians and philosophers about their common concerns. Our meetings were most exciting when we managed to glimpse an alternative.
There’s plenty of other good stuff in the book, including some famous pieces like Thurston’s classic On proof and progress in mathematics, and a couple of reprinted sections of Lakatos’s Proofs and Refutations.
Anyway, here are the notes. Anything I’ve put in quotes is Grabiner. Anything in square brackets is some random tangent I’ve gone off on.
Two “generalizations about the way many eighteenth-century mathematicians worked”:
“… the primary emphasis was on getting results”. Huge explosion in creativity, but “the chances are good that these results were originally obtained in ways utterly different from the ways we prove them today. It is doubtful that Euler and his contemporaries would have been able to derive their results if they had been burdened with our standards of rigor”.
“… mathematicians placed great reliance on the power of symbols. Sometimes it seems to have been assumed that if one could just write down something which was symbolically coherent, the truth of the statement was guaranteed.” This extended to e.g. manipulating infinite power series just like very long polynomials.
Euler’s Taylor expansion of starting from the binomial expansion as one example. He takes as infinitely small and as infinitely large, and is happy to assume their product is finite without worrying too much. “The modern reader may be left slightly breathless”, but he gets the right answer.
Trust in symbol manipulation was “somewhat anomalous in the history of mathematics”. Grabiner suggests it came from the recent success of algebra and the calculus. E.g. Leibniz’s notation, which “does the thinking for us” (chain rule as example). This also extended out of maths, e.g. Lavoisier’s idea of ‘chemical algebra’.
18th c was interested in foundations (e.g. Berkeley on calculus being insufficiently rigorous) but this was “not the basic concern” and generally was “relegated to Chapter I of textbooks, or found in popularizations”, not in research papers.
This changed in the 19th c beginning with Cauchy and Bolzano – beginnings of rigorous treatments of limits, continuity etc.
Why did standards change?
“The first explanation which may occur to us is like the one we use to justify rigor to our students today: the calculus was made rigorous to avoid errors, and to correct errors already made.” Doesn’t really hold up – there were surprisingly few mistakes in the 18th c stuff as they “had an almost unerring intuition”.
[I’ve been meaning to look into this for a while, as I get sick of that particular justification being trotted out, always with the same dubious examples. One of these is Weierstrass’s continuous-everywhere-differentiable-nowhere function. This is a genuine example of something the less rigorous approach failed to find, but it came much later, so isn’t what got people started on rigour.
The other example normally given is about something called “the Italian school of algebraic geometry”, which apparently went off the rails in the early 20th c and published false stuff. There’s some information on that in the answers to a MathOverflow question by Kevin Buzzard and the linked email from David Mumford – from a quick read it looks like it was one guy, Severi, who really lost it. Anyway, this is also a lot later than the 18th century.]
It is true though that by the end of the 18th c they were getting into topics – complex functions, multivariable calculus – where “there are many plausible conjectures whose truth is relatively difficult to evaluate intuitively”, so rigour was more useful.
Second possible explanation – need to unify the mass of results thrown up in the 18th c. Probably some truth to this: current methods were hitting diminishing returns, time to “sit back and reflect”.
Third explanation – prior existence of rigour in Euclid’s geometry. Berkeley’s attack on calculus was on this line.
One other interesting factor she suggests – an increasing need for mathematicians to teach (as they became employees of government-sponsored institutions rather than being attached to royal courts). École Polytechnique as model for these.
“Teaching always makes the teacher think carefully about the basis for the subject”. Moving from self-educated or apprentice-master set-ups, where you learn piecemeal from examples of successful thinking, to a more formalised ‘here are the foundations’ approach.
Her evidence – origins of foundational work often emerged from lecture courses. This was true for Lagrange, Cauchy, Weierstrass and Dedekind.
[I don’t know how strong this evidence is, but it’s a really interesting theory. I’ve had literalbanana‘s blog post on indexicality thoroughly stuck in my head for the last month, so I’m seeing that idea everywhere – this is one example. Teaching a large class forces you to take knowledge that was previously highly situated and indexical – ‘oh yes, you need to do this’ – and pull it out into a public form that makes sense to people not deeply immersed in that context. Compare Thurston’s quote in Proof and progress in mathematics: “When a significant theorem is proved, it often (but not always) happens that the solution can be communicated in a matter of minutes from one person to another within the subfield. The same proof would be communicated and generally understood in an hour talk to members of the subfield. It would be the subject of a 15- or 20-page paper, which could be read and understood in a few hours or perhaps days by members of the subfield.”]
How did standards change?
Often 18th c methods were repurposed/generalised. E.g. haphazard comparisons of particular series to the geometric series became Cauchy’s general convergence tests. Or old methods of computing the error term epsilon for the nth approximation get turned round, so that we are given epsilon and show we can always find n to beat that error term. This is essentially the definition of convergence we still use today.
Conclusion
Goes back to original question: is mathematical truth time-dependent? Sets up two bad options to knock down…
Relativism. “‘Sufficient unto the day is the rigor thereof.’ Mathematical truth is just what the editors of the Transactions say it is.” This wouldn’t explain why Cauchy and Weierstrass were ever unsatisfied in the first place.
MAXIMAL RIGOUR AT ALL TIMES. The 18th c was just sloppy. “According to this high standard, which textbooks sometimes urge on students, Euler would never have written a line.”
[A lot of my grumpiness about rigour is because it was exactly what I didn’t need as a first year maths student. I was just exploring the 18th century explosion myself and discovering the power of mathematics, and what I needed right then was to be able to run with that and learn more cool shit, without fussing over precise epsilon-delta definitions. Maybe it would have worked for me a couple of years later, if I’d seen enough examples to have come across a situation where rigour was useful. This seems to vary a lot though – David Chapman replied that lack of rigour was what he was annoyed by at that age, and he was driven to the library to read about Dedekind cuts.]
… then suggests “a third possibility”:
A Kuhnian picture where mathematics grows “not only by successive increments, but also by occasional revolutions”. “We can be consoled that most of the old bricks will find places somewhere in the new structure”.
I’ve been looking back at some of the mess I produced while trying to get an initial grip on the ideas I wrote up in my lasttwo posts on negative probability. One of my main interests in this blog is the gulf between maths as it is formally written up and the weird informal processes that produce mathematical ideas in the first place, so I thought this might make a kind of mini case study. Apologies in advance for my handwriting.
I do all my work in cheap school-style exercise books. The main thread of what I’m thinking about goes front-to-back: that’s where anything reasonably well-defined that I’m trying to do will go. Working through lecture notes, doing exercises, any calculations where I’m reasonably clear on what I’m actually calculating. But if I have no idea what I’m even trying to do, it goes in the back, instead. The back has all kinds of scribbles and disorganised crap:
The Spekkens toy model looks like Battenberg cake.
Most of it is no good, but new ideas also tend to come from the back. The Wigner function decomposition was definitely a back-of-the-book kind of thing. I’ve mostly forgotten what I was thinking when I made all these scribblings, and I wouldn’t trust the remembered version even if I had one, so I’ll try to refrain from too much analysis.
The idea seems to originate here:
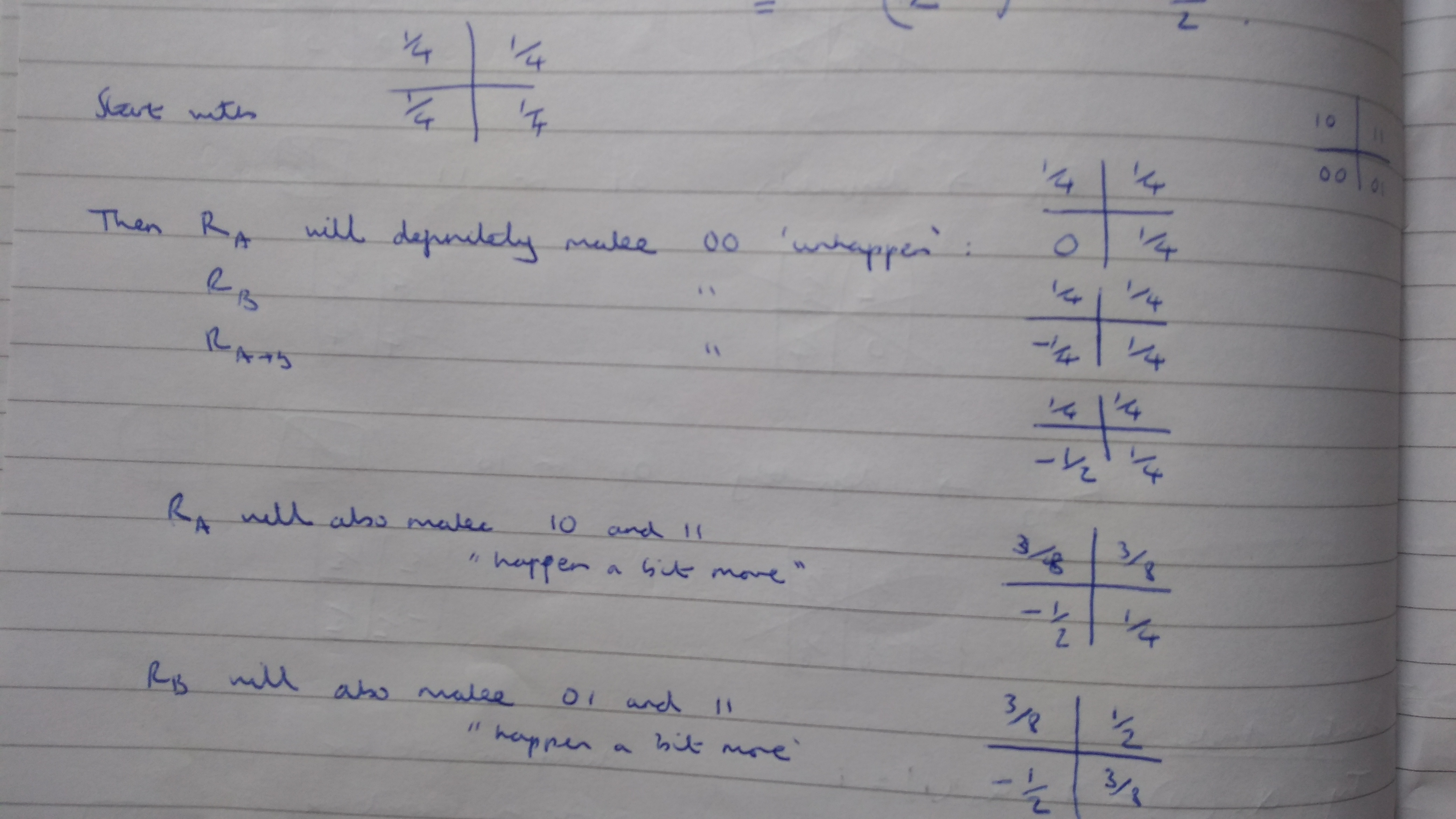
This has the key idea already: start with equal probability for all squares, and then add on correction terms until the bottom left corner goes negative. But the numbers are complete bullshit! Looking back, I can’t make sense of them at all. For instance, I was trying to add to things, instead of . Why? No idea! It’s not like is a number that had come up in any of my previous calculations, so I have no idea what I was thinking.
Even with the bullshit numbers, I must have had some inkling that this line of thought was worth pursuing, so I wrote it out again. This time I realised the numbers were wrong and crossed them out, writing the correct ones to the right:
The little squares above the main squares are presumably to tell me what to do: add to the filled in squares and subtract it from the blank ones.
I then did a sanity check on an example with no negative probabilities, and it worked:
At that point, I think I was convinced it worked in general, even though I’d only checked two cases. So I moved to the front of the book. After that, the rest of it looks like actual legit maths that a sane person would do, so it’s not so interesting. But I had to produce this mess to get there.
In this post, I’m going to assume you’ve come across the Cognitive Reflection Test before and know the answers. If you haven’t, it’s only three quick questions, go and do it now.
Bat & Ball train station, Sevenoaks [source]
One of the striking early examples in Kahneman’s Thinking, Fast and Slow is the following problem:
(1) A bat and a ball cost $1.10 in total. The bat costs $1.00 more than the ball.
Almost everyone we ask reports an initial tendency to answer “10 cents” because the sum $1.10 separates naturally into $1 and 10 cents, and 10 cents is about the right magnitude. Many people yield to this immediate impulse. The surprisingly high rate of errors in this easy problem illustrates how lightly System 2 monitors the output of System 1: people are not accustomed to thinking hard, and are often content to trust a plausible judgment that quickly comes to mind.
In Thinking, Fast and Slow, the bat and ball problem is used as an introduction to the major theme of the book: the distinction between fluent, spontaneous, fast ‘System 1’ mental processes, and effortful, reflective and slow ‘System 2’ ones. The explicit moral is that we are too willing to lean on System 1, and this gets us into trouble:
The bat-and-ball problem is our first encounter with an observation that will be a recurrent theme of this book: many people are overconfident, prone to place too much faith in their intuitions. They apparently find cognitive effort at least mildly unpleasant and avoid it as much as possible.
This story is very compelling in the case of the bat and ball problem. I got this problem wrong myself when I first saw it, and still find the intuitive-but-wrong answer very plausible looking. I have to consciously remind myself to apply some extra effort and get the correct answer.
However, this becomes more complicated when you start considering other tests of this fast-vs-slow distinction. Frederick later combined the bat and ball problem with two other questions to create the Cognitive Reflection Test:
(2) If it takes 5 machines 5 minutes to make 5 widgets, how long would it take 100 machines to make 100 widgets? _____ minutes
(3) In a lake, there is a patch of lily pads. Every day, the patch doubles in size. If it takes 48 days for the patch to cover the entire lake, how long would it take for the patch to cover half of the lake? _____ days
These are designed to also have an ‘intuitive-but-wrong’ answer (100 minutes, 24 days), and an ‘effortful-but-right’ answer (5 minutes, 47 days). But this time I seem to be immune to the wrong answers, in a way that just doesn’t happen with the bat and ball:
I always have the same reaction, and I don’t know if it’s common or I’m just the lone idiot with this problem. The ‘obvious wrong answers’ for 2. and 3. are completely unappealing to me (I had to look up 3. to check what the obvious answer was supposed to be). Obviously the machine-widget ratio hasn’t changed, and obviously exponential growth works like exponential growth.
When I see 1., however, I always think ‘oh it’s that bastard bat and ball question again, I know the correct answer but cannot see it’. And I have to stare at it for a minute or so to work it out, slowed down dramatically by the fact that Obvious Wrong Answer is jumping up and down trying to distract me.
If this test was really testing my propensity for effortful thought over spontaneous intuition, I ought to score zero. I hate effortful thought! As it is, I score two out of three, because I’ve trained my intuitions nicely for ratios and exponential growth. The ‘intuitive’, ‘System 1’ answer that pops into my head is, in fact, the correct answer, and the supposedly ‘intuitive-but-wrong’ answers feel bad on a visceral level. (Why the hell would the lily pads take the same amount of time to cover the second half of the lake as the first half, when the rate of growth is increasing?)
The bat and ball still gets me, though. My gut hasn’t internalised anything useful, and it’s super keen on shouting out the wrong answer in a distracting way. My dislike for effortful thought is definitely a problem here.
I wanted to see if others had raised the same objection, so I started doing some research into the CRT. In the process I discovered a lot of follow-up work that makes the story much more complex and interesting.
I’ve come nowhere near to doing a proper literature review. Frederick’s original paper has been cited nearly 3000 times, and dredging through that for the good bits is a lot more work than I’m willing to put in. This is just a summary of the interesting stuff I found on my limited, partial dig through the literature.
Thinking, inherently fast and inherently slow
Frederick’s original Cognitive Reflection Test paper describes the System 1/System 2 divide in the following way:
Recognizing that the face of the person entering the classroom belongs to your math teacher involves System 1 processes — it occurs instantly and effortlessly and is unaffected by intellect, alertness, motivation or the difficulty of the math problem being attempted at the time. Conversely, finding to two decimal places without a calculator involves System 2 processes — mental operations requiring effort, motivation, concentration, and the execution of learned rules.
I find it interesting that he frames mental processes as being inherently effortless or effortful, independent of the person doing the thinking. This is not quite true even for the examples he gives — faceblind people and calculating prodigies exist.
This framing is important for interpreting the CRT. If the problem inherently has a wrong ‘System 1 solution’ and a correct ‘System 2 solution’, the CRT can work as intended, as an efficient tool to split people by their propensity to use one strategy or the other. If there are ‘System 1’ ways to get the correct answer, the whole thing gets much more muddled, and it’s hard to disentangle natural propensity to reflection from prior exposure to the right mathematical concepts.
My tentative guess is that the bat and ball problem is close to being this kind of efficient tool. Although in some ways it’s the simplest of the three problems, solving it in a ‘fast’, ‘intuitive’ way relies on seeing the problem in a way that most people’s education won’t have provided. (I think this is true, anyway – I’ll go into more detail later.) I suspect that this is less true the other two problems – ratios and exponential growth are topics that a mathematical or scientific education is more likely to build intuition for.
(Aside: I’d like to know how these other two problems were chosen. The paper just states the following:
Motivated by this result [the answers to the bat and ball question], two other problems found to yield impulsive erroneous responses were included with the “bat and ball” problem to form a simple, three-item “Cognitive Reflection Test” (CRT), shown in Figure 1.
I have a vague suspicion that Frederick trawled through something like ‘The Bumper Book of Annoying Riddles’ to find some brainteasers that don’t require too much in the way of mathematical prerequisites. The lilypads one has a family resemblance to the classic grains-of-wheat-on-a-chessboard puzzle, for instance.)
However, I haven’t found any great evidence either way for this guess. The original paper doesn’t break down participants’ scores by question – it just gives mean scores on the test as a whole. I did however find this meta-analysis of 118 CRT studies, which shows that the bat and ball question is the most difficult on average – only 32% of all participants get it right, compared with 40% for the widgets and 48% for the lilypads. It also has the biggest jump in success rate when comparing university students with non-students. That looks like better mathematical education does help on the bat and ball, but it doesn’t clear up how it helps. It could improve participants’ ability to intuitively see the answer. Or it could improve ability to come up with an ‘unintuitive’ solution, like solving the corresponding simultaneous equations by a rote method.
What I’d really like is some insight into what individual people actually do when they try to solve the problems, rather than just this aggregate statistical information. I haven’t found exactly what I wanted, but I did turn up a few interesting studies on the way.
No, seriously, the answer isn’t ten cents
My favourite thing I found was this (apparently unpublished) ‘extremely rough draft’ by Meyer, Spunt and Frederick from 2013, revisiting the bat and ball problem. The intuitive-but-wrong answer turns out to be extremely sticky, and the paper is basically a series of increasingly desperate attempts to get people to actually think about the question.
One conjecture for what people are doing when they get this question wrong is the attribute substitution hypothesis. This was suggested early on by Kahneman and Frederick, and is a fancy way of saying that they are instead solving the following simpler problem:
(1) A bat and a ball cost $1.10 in total. The bat costs $1.00.
How much does the ball cost? _____ cents
Notice that this is missing the ‘more than the ball’ clause at the end, turning the question into a much simpler arithmetic problem. This simple problem does have ‘ten cents’ as the answer, so it’s very plausible that people are getting confused by it.
Meyer, Spunt and Frederick tested this hypothesis by getting respondents to recall the problem from memory. This showed a clear difference: 94% of ‘five cent’ respondents could recall the correct question, but only 61% of ‘ten cent’ respondents. It’s possible that there is a different common cause of both the ‘ten cent’ response and misremembering the question, but it at least gives some support for the substitution hypothesis.
However, getting people to actually answer the question correctly was a much more difficult problem. First they tried bolding the words more than the ball to make this clause more salient. This made surprisingly little impact: 29% of respondents solved it, compared with 24% for the original problem. Printing both versions was slightly more successful, bumping up the correct response to 35%, but it was still a small effect.
After this, they ditched subtlety and resorted to pasting these huge warnings above the question:
These were still only mildly effective, with a correct solution jumping to 50% from 45%. People just really like the answer ‘ten cents’, it seems.
At this point they completely gave up and just flat out added “HINT: 10 cents is not the answer.” This worked reasonably well, though there was still a hard core of 13% who persisted in writing down ‘ten cents’.
That’s where they left it. At this point there’s not really any room to escalate beyond confiscating the respondents’ pens and prefilling in the answer ‘five cents’, and I worry that somebody would still try and scratch in ‘ten cents’ in their own blood. The wrong answer is just incredibly compelling.
So, what are people doing when they solve this problem?
Unfortunately, it’s hard to tell from the published literature (or at least what I found of it). What I’d really like is lots of transcripts of individuals talking through their problem solving process. The closest I found was this paper by Szaszi et al, who did carry out these sort of interview, but it doesn’t include any examples of individual responses. Instead, it gives a aggregated overview of types of responses, which doesn’t go into the kind of detail I’d like.
Still, the examples given for their response categories give a few clues. The categories are:
Correct answer, correct start. Example given: ‘I see. This is an equation. Thus if the ball equals to x, the bat equals to x plus 1… ‘
Correct answer, incorrect start. Example: ‘I would say 10 cents… But this cannot be true as it does not sum up to €1.10…’
Incorrect answer, reflective, i.e. some effort was made to reconsider the answer given, even if it was ultimately incorrect. Example: ‘… but I’m not sure… If together they cost €1.10, and the bat costs €1 more than the ball… the solution should be 10 cents. I’m done.’
No reflection. Example: ‘Ok. I’m done.’
These demonstrate one way to reason your way to the correct answer (solve the simultaneous equations) and one way to be wrong (just blurt out the answer). They also demonstrate one way to recover from an incorrect solution (think about the answer you blurted out and see if it actually works). Still, it’s all rather abstract and high level.
How To Solve It
However, I did manage to stumble onto another source of insight. While researching the problem I came across this article from the online magazine of the Association for Psychological Science, which discusses a variant ‘Ford and Ferrari problem’. This is quite interesting in itself, but I was most excited by the comments section. Finally some examples of how the problem is solved in the wild!
The simplest ‘analytical’, ‘System 2’ solution is to rewrite the problem as two simultaneous linear equations and plug-and-chug your way to the correct answer. For example, writing for the bat and for the ball, we get the two equations
, ,
which we could then solve in various standard ways, e.g.
, ,
which then gives
.
There are a couple of variants of this explained in the comments. It’s a very reliable way to tackle the problem: if you already know how to do this sort of rote method, there are no surprises. This sort of method would work for any similar problem involving linear equations.
However, it’s pretty obvious that a lot of people won’t have access to this method. Plenty of people noped out of mathematics long before they got to simultaneous equations, so they won’t be able to solve it this way. What might be less obvious, at least if you mostly live in a high-maths-ability bubble, is that these people may also be missing the sort of tacit mathematical background that would even allow them to frame the problem in a useful form in the first place.
That sounds a bit abstract, so let’s look at some responses (I’ll paste all these straight in, so any typos are in the original). First, we have these two confused commenters:
The thing is, why does the ball have to be $.05? It could have been .04 0r.03 and the bat would still cost more than $1.
and
This is exactly what bothers me and resulted in me wanting to look up the question online. On the quiz the other 2 questions were definitive. This one technically could have more than one answer so this is where phycologists actually mess up when trying to give us a trick question. The ball at .4 and the bat at 1.06 doesn’t break the rule either.
These commenters don’t automatically see two equations in two variables that together are enough to constrain the problem. Instead they seem to focus mainly on the first condition (adding up to $1.10) and just use the second one as a vague check at best (‘the bat would still cost more than $1’). This means that they are unable to immediately tell that the problem has a unique solution.
In response, another commenter, Tony, suggests a correct solution which is an interesting mix of writing the problem out formally and then figuring out the answer by trial and error:
I hear your pain. I feel as though psychologists and psychiatrists get together every now and then to prove how stoopid I am. However, after more than a little head scratching I’ve gained an understanding of this puzzle. It can be expressed as two facts and a question A=100+B and A+B=110, so B=? If B=2 then the solution would be 100+2+2 and A+B would be 104. If B=6 then the solution would be 100+6+6 and A+B would be 112. But as be KNOW A+B=110 the only number for B on it’s own is 5.
This suggests enough half-remembered mathematical knowledge to find a sensible abstract framing, but not enough to solve it the standard way.
Finally, commenter Marlo Eugene provides an ingenious way of solving the problem without writing all the algebraic steps out:
Linguistics makes all the difference. The conceptual emphasis seems to lie within the word MORE.
X + Y = $1.10. If X = $1 MORE then that leaves $0.10 TO WORK WITH rather than automatically assign to Y
So you divide the remainder equally (assuming negative values are disqualified) and get 0.05.
So even this small sample of comments suggests a wide diversity of problem-solving methods leading to the two common answers. Further, these solutions don’t all split neatly into ‘System 1’ ‘intuitive’ and ‘System 2’ ‘analytic’. Marlo Eugene’s solution, for instance, is a mixed solution of writing the equations down in a formal way, but then finding a clever way of just seeing the answer rather than solving them by rote.
I’d still appreciate more detailed transcripts, including the time taken to solve the problem. My suspicion is still that very few people solve this problem with a fast intuitive response, in the way that I rapidly see the correct answer to the lilypad question. Even the more ‘intuitive’ responses, like Marlo Eugene’s, seem to rely on some initial careful reflection and a good initial framing of the problem.
If I’m correct about this lack of fast responses, my tentative guess for the reason is that it has something to do with the way most of us learn simultaneous equations in school. We generally learn arithmetic as young children in a fairly concrete way, with the formal numerical problems supplemented with lots of specific examples of adding up apples and bananas and so forth.
But then, for some reason, this goes completely out of the window once the unknown quantity isn’t sitting on its own on one side of the equals sign. This is instead hived off into its own separate subject, called ‘algebra’, and the rules are taught much later in a much more formalised style, without much attempt to build up intuition first.
(One exception is the sort of puzzle sheets that are often given to young kids, where the unknowns are just empty boxes to be filled in. Sometimes you get 2+3=□, sometimes it’s 2+□=5, but either way you go about the same process of using your wits to figure out the answer. Then, for some reason I’ll never understand, the worksheets get put away and the poor kids don’t see the subject again until years later, when the box is now called for some reason and you have to find the answer by defined rules. Anyway, this is a separate rant.)
This lack of a rich background in puzzling out the answer to specific concrete problems means most of us lean hard on formal rules in this domain, even if we’re relatively mathematically sophisticated. Only a few build up the necessary repertoire of tricks to solve the problem quickly by insight. I’m reminded of a story in Feynman’s The Pleasure of Finding Things Out:
Around that time my cousin, who was three years older, was in high school. He was having considerable difficulty with his algebra, so a tutor would come. I was allowed to sit in a corner while the tutor would try to teach my cousin algebra. I’d hear him talking about x.
I said to my cousin, “What are you trying to do?”
“I’m trying to find out what x is, like in 2x + 7 = 15.”
I say, “You mean 4.”
“Yeah, but you did it by arithmetic. You have to do it by algebra.”
I learned algebra, fortunately, not by going to school, but by finding my aunt’s old schoolbook in the attic, and understanding that the whole idea was to find out what x is – it doesn’t make any difference how you do it.
I think this reliance on formal methods might be somewhat less true for exponential growth and ratios, the subjects underpinning the lilypad and widget questions. Certainly I seem to have better intuition there, without having to resort to rote calculation. But I’m not sure how general this is.
How To Visualise It
If you wanted to solve the bat and ball problem without having to ‘do it by algebra’, how would you go about it?
My original post on the problem was a pretty quick, throwaway job, but over time it picked up some truly excellent comments by anders and Kyzentun, which really start to dig into the structure of the problem and suggest ways to ‘just see’ the answer. The thread with anders in particular goes into lots of other examples of how we think through solving various problems, and is well worth reading in full. I’ll only summarise the bat-and-ball-related parts of the comments here.
We all used some variant of the method suggested by Marlo Eugene in the comments above. Writing out the basic problem again, we have:
, .
Now, instead of immediately jumping to the standard method of eliminating one of the variables, we can just look at what these two equations are saying and solve it directly ‘by thinking’. We have a bat, . If you add the price of the ball, , you get 110 cents. If you instead remove the same quantity you get 100 cents. So the bat’s price must be exactly halfway between these two numbers, at 105 cents. That leaves five for the ball.
Now that I’m thinking of the problem in this way, I directly see the equations as being ‘about a bat that’s halfway between 100 and 110 cents’, and the answer is incredibly obvious.
Kyzentun suggests a variant on the problem that is much less counterintuitive than the original:
A centered piece of text and its margins are 110 columns wide. The text is 100 columns wide. How wide is one margin?
Same numbers, same mathematical formula to reach the solution. But less misleading because you know there are two margins, and thus know to divide by two after subtracting.
In the original problem, the 110 units and 100 units both refer to something abstract, the sum and difference of the bat and ball. In Kyzentun’s version these become much more concrete objects, the width of the text and the total width of the margins. The work of seeing the equations as relating to something concrete has mostly been done for you.
Similarly, anders works the problem by ‘getting rid of the 100 cents’, and splitting the remainder in half to get at the price of the ball:
I just had an easy time with #1 which I haven’t before. What I did was take away the difference so that all the items are the same (subtract 100), evenly divide the remainder among the items (divide 10 by 2) and then add the residuals back on to get 105 and 5.
The heuristic I seem to be using is to treat objects as made up of a value plus a residual. So when they gave me the residual my next thought was “now all the objects are the same, so whatever I do to one I do to all of them”.
I think that after reasoning my way through all these perspectives, I’m finally at the point where I have a quick, ‘intuitive’ understanding of the problem. But it’s surprising how much work it was for such a simple bit of algebra.
Final thoughts
Rather than making any big conclusions, the main thing I wanted to demonstrate in this post is how complicated the story gets when you look at one problem in detail. I’ve written about close reading recently, and this has been something like a close reading of the bat and ball problem.
Frederick’s original paper on the Cognitive Reflection Test is in that generic social science style where you define a new metric and then see how it correlates with a bunch of other macroscale factors (either big social categories like gender or education level, or the results of other statistical tests that try to measure factors like time preference or risk preference). There’s a strange indifference to the details of the test itself – at no point does he discuss why he picked those specific three questions, and there’s no attempt to model what was making the intuitive-but-wrong answer appealing.
The later paper by Meyer, Spunt and Frederick is much more interesting to me, because it really starts to pick apart the specifics of the bat and ball problem. Is an easier question getting substituted? Can participants reproduce the correct question from memory?
I learned the most from the individual responses, though, and seeing the variety of ways people go about solving the problem. It’s very strange to me that I had an easier time digging this out from an internet comment thread than the published literature! I would love to see a lot more research into what people actually do when they do mathematics, and the bat and ball problem would be a great place to start.
Questions
I’m interested in any comments on the post, but here are a few specific things I’d like to get your answers to:
My rapid, intuitive answer for the bat and ball question is wrong (at least until I retrained it by thinking about the problem way too much). However, for the other two I ‘just see’ the correct answer. Is this common for other people, or do you have a different split?
If you’re able to rapidly ‘just see’ the answer to the bat and ball question, how do you do it?
How do people go about designing tests like these? This isn’t at all my field and I’d be interested in any good sources. I’d kind of assumed that there’d be some kind of serious-business Test Creation Methodology, but for the CRT at least it looks like people just noticed they got surprising answers for the bat and ball question and looked around for similar questions. Is that unusual compared to other psychological tests?
[I’ve cross-posted this at LessWrong, because I thought the topic fits quite nicely – comments at either place are welcome.]
(I posted this on Less Wrong back in April and forgot to cross post here. It’s just the same references I’ve posted before, but it’s worth reading over there for the comments, which are great.)
This is an expansion of a linkdump I made a while ago with examples of mathematicians splitting other mathematicians into two groups, which may be of wider interest in the context of the recent elephant/rider discussion. (Though probably not especially wide interest, so I’m posting this to my personal page.)
The two clusters vary a bit, but there’s some pattern to what goes in each – it tends to be roughly ‘algebra/problem-solving/analysis/logic/step-by-step/precision/explicit’ vs. ‘geometry/theorising/synthesis/intuition/all-at-once/hand-waving/implicit’.
(Edit to add: ‘analysis’ in the first cluster is meant to be analysis as opposed to ‘synthesis’ in the second cluster, i.e. ‘breaking down’ as opposed to ‘building up’. It’s not referring to the mathematical subject of analysis, which is hard to place!)
These seem to have a family resemblance to the S2/S1 division, but there’s a lot lumped under each one that could helpfully be split out, which is where some of the confusion in the comments to the elephant/rider post is probably coming in. (I haven’t read The Elephant in the Brain yet, but from the sound of it that is using something of a different distinction again, which is also adding to the confusion). Sarah Constantin and Owen Shen have both split out some of these distinctions in a more useful way.
I wanted to chuck these into the discussion because: a) it’s a pet topic of mine that I’ll happily shoehorn into anything; b) it shows that a similar split has been present in mathematical folk wisdom for at least a century; c) these are all really good essays by some of the most impressive mathematicians and physicists of the 20th century, and are well worth reading on their own account.
“It is impossible to study the works of the great mathematicians, or even those of the lesser, without noticing and distinguishing two opposite tendencies, or rather two entirely different kinds of minds. The one sort are above all preoccupied with logic; to read their works, one is tempted to believe they have advanced only step by step, after the manner of a Vauban who pushes on his trenches against the place besieged, leaving nothing to chance.
The other sort are guided by intuition and at the first stroke make quick but sometimes precarious conquests, like bold cavalrymen of the advance guard.”
Felix Klein’s ‘Elementary Mathematics from an Advanced Standpoint’ in 1908 has ‘Plan A’ (‘the formal theory of equations’) and ‘Plan B’ (‘a fusion of the perception of number with that of space’). He also separates out ‘ordered formal calculation’ into a Plan C.
Gian-Carlo Rota made a division into ‘problem solvers and theorizers’ (in ‘Indiscrete Thoughts’, excerpt here).
Timothy Gowers makes a very similar division in his ‘Two Cultures of Mathematics’ (discussion and link to pdf here).
Vladimir Arnold’s ‘On Teaching Mathematics’ is an incredibly entertaining rant from a partisan of the geometry/intuition side – it’s over-the-top but was 100% what I needed to read when I first found it.
Broadly speaking I want to suggest that geometry is that part of mathematics in which visual thought is dominant whereas algebra is that part in which sequential thought is dominant. This dichotomy is perhaps better conveyed by the words “insight” versus “rigour” and both play an essential role in real mathematical problems.
There’s also his famous quote:
Algebra is the offer made by the devil to the mathematician. The devil says: `I will give you this powerful machine, it will answer any question you like. All you need to do is give me your soul: give up geometry and you will have this marvellous machine.’
Grothendieck was seriously weird, and may not fit well to either category, but I love this quote from Récoltes et semailles too much to not include it:
Since then I’ve had the chance in the world of mathematics that bid me welcome, to meet quite a number of people, both among my “elders” and among young people in my general age group who were more brilliant, much more ‘gifted’ than I was. I admired the facility with which they picked up, as if at play, new ideas, juggling them as if familiar with them from the cradle – while for myself I felt clumsy, even oafish, wandering painfully up an arduous track, like a dumb ox faced with an amorphous mountain of things I had to learn (so I was assured), things I felt incapable of understanding the essentials or following through to the end. Indeed, there was little about me that identified the kind of bright student who wins at prestigious competitions or assimilates almost by sleight of hand, the most forbidding subjects.
In fact, most of these comrades who I gauged to be more brilliant than I have gone on to become distinguished mathematicians. Still from the perspective or thirty or thirty five years, I can state that their imprint upon the mathematics of our time has not been very profound. They’ve done all things, often beautiful things, in a context that was already set out before them, which they had no inclination to disturb. Without being aware of it, they’ve remained prisoners of those invisible and despotic circles which delimit the universe of a certain milieu in a given era. To have broken these bounds they would have to rediscover in themselves that capability which was their birthright, as it was mine: The capacity to be alone.
Freeman Dyson calls his groups ‘Birds and Frogs’ (this one’s more physics-focussed).
This may be too much partisanship from me for the geometry/implicit cluster, but I think the Mark Kac ‘magician’ quote is also connected to this:
There are two kinds of geniuses: the ‘ordinary’ and the ‘magicians.’ an ordinary genius is a fellow whom you and I would be just as good as, if we were only many times better. There is no mystery as to how his mind works. Once we understand what they’ve done, we feel certain that we, too, could have done it. It is different with the magicians… Feynman is a magician of the highest caliber.
The algebra/explicit cluster is more ‘public’ in some sense, in that its main product is a chain of step-by-step formal reasoning that can be written down and is fairly communicable between people. (This is probably also the main reason that formal education loves it.) The geometry/implicit cluster relies on lots of pieces of hard-to-transfer intuition, and these tend to stay ‘stuck in people’s heads’ even if they write a legitimising chain of reasoning down, so it can look like ‘magic’ on the outside.
Edit to add: Seo Sanghyeon contributed the following example by email, from Weinberg’s Dreams of a Final Theory:
Theoretical physicists in their most successful work tend to play one of two roles: they are either sages or magicians… It is possible to teach general relativity today by following pretty much the same line of reasoning that Einstein used when he finally wrote up his work in 1915. Then there are magician-physicists, who do not seem to be reasoning at all but who jump over all intermediate steps to a new insight about nature. The authors of physics textbook are usually compelled to redo the work of the magicians so they seem like sages; otherwise no reader would understand the physics.
I’ve recently been browsing through Season 1 of Venkatesh Rao’s Breaking Smart newsletter. I didn’t sign up for this originally because I assumed it was some kind of business thing I wouldn’t care about, but I should have realised it wouldn’t stray far from the central Ribbonfarm obsessions. In particular, there’s an emphasis on my favourite one: figuring out how to make progress in domains where the questions you are asking are still fuzzy and ambiguous.
‘Is there a there there? You’ll know when you find it’ is explicitly about this, and even better, it links to an interesting article that ties in to one of my central obsessions, the perennial ‘two types of mathematician’ question. It’s just a short Wired article without a lot of detail, but the authors have also written a pop science book it’s based on, The Eureka Factor. From the blurb it looks very poppy, but also extremely close to my interests, so I plan to read it. If I had any sense I’d do this before I started writing about it, but this braindump somehow just appeared anyway.
The book is not focussed on maths – it’s a general interest book about problem solving and creativity in any domain. But it looks like it has a very similar way of splitting problem solvers into two groups, ‘insightfuls’ and ‘analysts’. ‘Analysts’ follow a linear, methodical approach to work through a problem step by step. Importantly, they also have cognitive access to those steps – if they’re asked what they did to solve the problem, they can reconstruct the argument.
‘Insightfuls’ have no such access to the way they solved the problem. Instead, a solution just ‘pops into their heads’.
Of course, nobody is really a pure ‘insightful’ or ‘analyst’. And most significant problems demand a mixed strategy. But it does seem like many people have a tendency towards one or the other.
A nice toy problem for thinking about how this works in maths is the one Seymour Papert discusses in a fascinating epilogue to his Mindstorms book. I’ve written about this before but I’m likely to want to return to it a lot, so it’s probably worth writing out in a more coherent form that the tumblr post.
Papert considers two proofs of the irrationality of the square root of two, “which differ along a dimension one might call ‘gestalt versus atomistic’ or ‘aha-single-flash-insight versus step-by-step reasoning’.” Both start with the usual proof by contradiction: let , a fraction expressed in its lowest terms, and rearrange it to get
The standard proof I learnt as a first year maths student does the job. You notice that must be even, so you write it as , sub it back in and notice that is going to have to be even too. But you started with the fraction expressed in its lowest terms, so the factors shouldn’t be there and you have a contradiction. Done.
This is a classic ‘analytical’ step-by-step proof, and it’s short and neat enough that it’s actually reasonably satisfying. But I much prefer Papert’s ‘aha-single-flash-insight’ proof.
Think of as a product of its prime factors, e.g. . Then will have an even number of each prime factor, e.g. .
But then our equation is saying that an even set of prime factors equals another even set multiplied by a 2 on its own, which makes no sense at all.
This proof still has some step-by-step analytical setup. You follow the same proof by contradiction method to start off with, and the idea of viewing and as prime factors still has to be preloaded into your head in a more-or-less logical way. But once you’ve done that, the core step is insight-based. You don’t need to think about why the original equation is wrong any more. You can just see it’s wrong by looking at it. In fact, I’m now surprised that it didn’t look wrong before!
For me, all of the fascination of maths is in this kind of insight step. And also most of the frustration… you can’t see into the black box properly, so what exactly is going on?
My real, selfish reason for being obsessed with this question is that my ability to do any form of explicit step-by-step reasoning in my head is rubbish. I would guess it’s probably bad compared to the average person; it’s definitely bad compared to most people who do maths.
This is a major problem in a few very narrow situations, such as trying to play a strategy game. I’m honestly not sure if I could remember how to draw at noughts and crosses, so trying to play anything with a higher level of sophistication is embarrassing.
Strategy games are pretty easy to avoid most of the time. (Though not as easy to avoid as I’d like, because most STEM people seem to love this crap 😦 ). But you’d think that this would be a serious issue in learning maths as well. It does slow me down a lot, sometimes, when trying to pick up a new idea. But it doesn’t seem to stop me making progress in the long run; somehow I’m managing to route round it. So what I’m trying to understand when I think about this question is how I’m doing this.
It’s hard to figure it out, but I think I use several skills. One is simply that I can follow the same chains of reasoning as everyone else, given enough time and a piece of paper. It’s not some sort of generalised ‘inability to think logically’, or then I suppose I really would be in the shit. Subjectively at least, it feels more like the bit of my brain that I have access to is extremely noisy and unfocussed, and has to be goaded through the steps in a very slow, explicit way.
Another skill I enjoy is building fluency, getting subtasks like bits of algebraic manipulation ‘under my fingers’ so I don’t have to think about them at all. This is the same as practising a musical instrument and I’m familiar with how to do it.
But the fun one is definitely insight. Whatever’s going on in Papert’s ‘aha-single-flash-insight’ is the whole reason why I do maths and physics, and I wish I understood it better. I also wish there were more resources for learning how to work with it, as I’m pretty sure it’s my main trick for working round my poor explicit reasoning skills.
My workflow for trying to understand a new concept is something like:
search John Baez’s website in the hope that he’s written about it;
google something like ‘[X] intuitively’ and pick out any fragments of insight I can find from blog posts, StackExchange answers and lecture notes;
(back when I had easy access to an academic library) pull a load of vaguely relevant books off the shelf and skim them;
resign myself to actually having to think for myself, and work through the simplest example I can find.
The aim is always to find something like Papert’s ‘set of prime factors’ insight, some key idea that makes the point of the concept pop out. For example, suppose I want to know about the Maurer-Cartan form in differential geometry, which has this fairly unilluminating definition on Wikipedia:
Then I’m done at step 1, because John Baez has this to say:
Let’s start with the Maurer-Cartan form. This is a gadget that shows up in the study of Lie groups. It works like this. Suppose you have a Lie group G with Lie algebra Lie(G). Suppose you have a tangent vector at any point of the group G. Then you can translate it to the identity element of G and get a tangent vector at the identity of G. But, this is nothing but an element of Lie(G)!
So, we have a god-given linear map from tangent vectors on G to the Lie algebra Lie(G). This is called a “Lie(G)-valued 1-form” on G, since an ordinary 1-form eats tangent vectors and spits out numbers, while this spits out elements of Lie(G). This particular god-given Lie(G)-valued 1-form on G is called the “Maurer-Cartan form”, and denoted ω.
This requires a lot more knowledge going in than the square root of two example, because I need to know what a Lie group and a Lie algebra and a 1-form are to get any use out of it. But if I’ve already struggled through getting the necessary insights for those things, I now have exactly the further insight I need: if you can translate your tangent vector back to the identity it’ll magically turn into a Lie algebra element, so then you’ve got yourself a map between the two sorts of things. And if I don’t know what a Lie group and a Lie algebra and a 1-form are, it’s pointless me trying to learn about the Maurer-Cartan form anyway.
Unfortunately, nobody has locked John Baez in a room and made him write about every topic in mathematics, so normally I have to go further down my algorithm, and that’s where things get difficult. There’s surprisingly poor support for an insight-based route through maths. If you want insights you have to dig for them, one piece at a time.
Presumably this is at least partially a hangover of the twentieth century’s obsession with formalism. Insights don’t look like proper logical maths with all the steps written out. You just sort of look at them, and the work’s mostly being done by a black box in your head. So this is definitely not a workflow I was taught by anyone during my maths degree; it’s one I improvised over time so that I could get through it anyway, when presented with definitions as opaque as the one from the Wikipedia article.
I’m confident that we can do better. And also that we will, as there seems to be an increasing interest in developing better conceptual explanations. I think Google’s Distill project and their idea of ‘research debt’ is especially promising. But that article’s interesting enough that it should really be a separate post sometime.
Note: these posts are copied over from the ‘mathbucket’ section of my old tumblr blog and I haven’t put much effort into this, so there is likely to be context or formatting missing.
Rereading a bit, that blog post comment section is probably the original source of my minor obsession with the role-of-intuition-in-maths literature.
(This isn’t actually a particularly major real-life obsession, just a secondary one that I like writing about/have worked out how to write about/have bored everyone I actually know with so I need to go talk about it somewhere else where people can opt out easily)
The only thing I can’t find in there is the Vladimir Arnold rant, which I must have picked up somewhere else. And actually Rota doesn’t make an appearance either. But there’s a load of the standard lore, the usual quotes from Thurston and Poincaré (it’s always the same quotes because this subfield is tiny).
I’d kind of forgotten that, because I think of it more as my starting point in figuring out how to learn differential geometry. Following the references in the comments taught me more than any maths course I took in undergrad.
Anyway, some highlights:
“I have a colleague (in CS, not math) who reads papers as follows: First he skims the paper by skipping all English and reading only formulas, then he reads the introduction, and then he reads again forcing himself to read some of the English too.”
that story about Grothendieck thinking that 57 was prime
“One day I realized it was all a lot clearer if I specialized the arguments. As a simple example, a theorem about differentiable real-valued functions on an interval might reduce to the case of the behavior, at 0, of a differentiable function f satisfying f(0) = 0 and f'(0) = 0. Cosmetic assumptions like these simplify the difference quotient and make the key issues clearer (to a novice anyway). The “general case” of such a theorem is often the result of composing the specific proof with an affine transformation. The symbols implementing this transformation play no essential role in the argument.”
Fields Medallist admits they never really understood what all that Sylow subgroup stuff was on about
”My undergraduate days left me afraid of many subjects: complex analysis, measure theory, most of algebra and almost all geometry, for example”
link to John Baez on normal subgroups. I gave up with trying to understand group theory when I didn’t understand what the definition of a normal subgroup was on about. Unfortunately this is like week 3 of an intro to group theory course, so that was kind of it for me and abstract algebra. I clicked on the link but never read it properly and still don’t really get what a normal subgroup is. Even so, after reading this I felt better for realising it wasn’t some completely obvious thing I ought to ‘just get’ and didn’t.
“Dualization is a rather simple idea but I think it is perhaps one of, if not the, most powerful tools in mathematics, especially in the modern era. There is, I’m sure, a good story about why. Perhaps someone can explain or tell me where to find an explanation?”
someone asks how to start learning differential geometry and a student of Chern turns up to answer
‘I like to call differential geometry “nonlinear linear algebra”.’
a long involved interesting argument about whether you should identify the tangent and cotangent space when you can to save bothering to keep track of a distinction you don’t need right now, or whether you’ll confuse yourself more in the long run
anecdote about helping a six-year-old who “could do 3+2 with no problem whatsoever. In fact, she had no trouble with addition. She just couldn’t get her head around all these wretched apples, cakes, monkeys etc that were being used to “explain” the concept of addition to her.”
“I was talking to two students about conjugation and talked about how gfg^{-1} is the function that takes g(x) to g(y) if f takes x to y. I then asked them to come up with a function from the reals to the reals that takes x^3 to (x+1)^3 for every x. After a while, one of them had the idea of taking the cube root, adding one, and cubing. But it was clear that he did that by forgetting all about my discussion of conjugation and just looking at the example. Only afterwards, when I pointed it out, did he realize that he had just done a conjugation.”
“Kazhdan’s advice to my friend: You should know everything in this book but don’t read it.”
Note: these posts are copied over from the ‘mathbucket’ section of my old tumblr blog and I haven’t put much effort into this, so there is likely to be context or formatting missing.
That education thing made me remember I wrote something about my maths teacher a few months ago as setup for a complex point that I never wrote down and have now completely forgotten. I’m probably not going to remember so let’s post it as is:
So I’m digging through some differential equation stuff trying to fill a few gaps in my knowledge, mostly arsing around ‘doing some prerequisites’ for quantum field theory instead of just jumping in. This time it’s the Fredholm Alternative. It looks like one of those bits of arcane mathematical methods textbook lore with the silly names, like the bilinear concomitant or Rayleigh’s quotient or ‘the method of undetermined coefficients’, which I always thought was just called ‘guessing’. This looks pretty useful and general though, looking at some inner product to see whether boundary value problems have one solution or no solutions or infinitely many solutions.
Actually it looks a bit like… oh, yeah, look, there’s even a matrix version. In fact,…
I’m in a classroom with the other Further Maths nerds. It doesn’t fit on the timetable so we’re stuck in there again after school, eating vending machine sweets and solving systems of simultaneous equations using Gaussian elimination. As always, our teacher has gone beyond the rote work of the syllabus and is making sure we understand what’s going on geometrically, using three planes as an example. We’re systematically working through the possibilities: all three planes parallel, two parallel and one crosses them (‘British Rail logo’), all three intersect along a single line, all the rest. We can end up with no solutions, or a unique solution at a single point, or a whole line or plane of solutions.
Then someone looks out the window. It’s someone’s brother in Year 8, mucking about on the flat roof across the playground. He thinks everyone’s gone home.
Our teacher opens the window, still caught up in his system of equations. “GET OFF THAT PLANE!!! NOW! YOU’RE IN DETENTION TOMORROW!”
And afterwards, as the kid complies: “…did I just say ‘plane’ instead of ‘roof’?”
We go back to the example. I get plenty more linear algebra next year at university, but however abstractly they dress it up, in my head it’s just the same old intersecting planes.
I’ve seen the words ‘Fredholm Alternative’ somewhere else, though, too, on one of my unmotivated afternoons in the library pulling books off the shelves. Ah yes, googling around it must have been Booss and Bleecker’s Index Theory, which aims to drag even applied mathematicians up to the heights:
Index Theory with Applications to Mathematics and Physics describes, explains, and explores the Index Theorem of Atiyah and Singer, one of the truly great accomplishments of twentieth-century mathematics whose influence continues to grow, fifty years after its discovery. The Index Theorem has given birth to many mathematical research areas and exposed profound connections between analysis, geometry, topology, algebra, and mathematical physics. Hardly any topic of modern mathematics stands independent of its influence.
And there’s the Fredholm Alternative in Chapter 2, one of the steps on the path.
Maybe I’m not just digging out random crap from the textbook. It looks like I accidentally found one of the Old Ways of mathematics, linking my A Level classes with some great confluence up in the stratosphere. With like a million steps above me still, but sometimes it’s nice just to know you’re on the path.
Note: these posts are copied over from the ‘mathbucket’ section of my old tumblr blog and I haven’t put much effort into this, so there is likely to be context or formatting missing.
I finally got nerd-sniped by the Arbital thing, so here are some rambly thoughts.
I’m definitely intrigued by the idea, because there are a lot of topics in maths that can be understood at very different levels. It’s true that there is often a level of understanding below which you have very little hope (e.g. @nostalgebraist‘s example of reading the integration by parts page without calculus). But often there are many tiers of understanding above the first. E.g. Thurston talking about different concepts of the derivative:
So I can see some potential here. However I’m not at all taken with the current implementation. The biggest dud for me is the clunky, prescriptive questionnaire interface over the top of it. I’m normally pretty good at identifying whether I can follow an explanation once I can actually see it, the main advantage I can see to the site is having many such explanations in the same place for easy access. I don’t want to be tediously clicking through branching pathways, like some Choose Your Own Adventure book where every adventure is just Bayes’s theorem again.
To my mind that part of Arbital’s just plain bad, but another aspect of the site that I don’t like may improve with time. At the moment it’s heavily curated, giving it a very homogeneous textbook feel. It sounds like the idea is to allow users with enough karma to contribute themselves, and then it may become more diverse.
I think the thing I would like is more *styles* of explanation rather than particularly different *levels*. For example, here’s the earlier part of Thurston’s list [this is such a wonderful paper, if for any misguided reason you are reading all this rubbish you should just go and read that instead :)]:
These are very different ways of thinking of a derivative, but I wouldn’t say that they are at different levels. I think different ones will appeal to different people, and your ideal starting point will vary depending on that. (Eventually you need to learn the others, of course, but initial motivation is important. For me (1) and (4) feel the most natural, and motivate me to learn the incredibly necessary (2), and even to deal with the tedium of (3)). I guess my ideal maths-explanation site would have a variety of explanations at each level.
[At which point, is it even worth trying to collect all this disparate stuff on one site? I honestly don’t know.]
My final bloody obvious objection is that politically they should definitely not have gone for Bayes’s theorem as a nice uncontroversial starting example instead of basically any other topic in mathematics, but, well, Yudkowsky and doing the politically sensible thing rarely go together.
Still, after all that grumbling I do appreciate any attempts at providing better explanations for mathematical concepts online. I find this stuff really interesting for some reason, and the idea I personally like to think about is an approach I call ‘examples first’, after thesetwo blog posts by Timothy Gowers. (The second one has an absolutely epic comment thread – reading that and following the links has taught me more maths than any single course I ever took at university.)
I always like to learn by following concrete worked examples. This may just be a personal preference, but it sounds from the blog post that it’s pretty common. In my case, out of the Arbital explanations the one I’d personally choose was the beginner-level one (so much for that questionnaire). I would always rather learn by doing problems about socks in a drawer than read an explanation in terms of some abstract variables A and B. If I’m learning maths from a textbook I always start by looking at the pictures and reading any waffly chunks of text, then look at the examples and exercises. I only grudgingly read the theory bit when I’m really stuck.
I guess what I would like is something like a repository of worked examples, where you search for a topic and then get a bunch of problems to try. Wikipedia generally ends up with a formalism-heavy approach, whereas I would always prefer to look at some specific function, or a matrix with actual numbers in it or something.
Note: these posts are copied over from the ‘mathbucket’ section of my old tumblr blog and I haven’t put much effort into this, so there is likely to be context or formatting missing.
The Cognitive Reflection Test came up in the SSC Superforecasters review. I’ve seen it a couple of times before, and it always interests me:
A bat and a ball cost $1.10 in total. The bat costs $1.00 more than the ball. How much does the ball cost?
If it takes 5 machines 5 minutes to make 5 widgets, how long would it take 100 machines to make 100 widgets?
In a lake, there is a patch of lily pads. Every day, the patch doubles in size. If it takes 48 days for the patch to cover the entire lake, how long would it take for the patch to cover half of the lake?
I always have the same reaction, and I don’t know if it’s common or I’m just the lone idiot with this problem. The ‘obvious wrong answers’ for 2. and 3. are completely unappealing to me (I had to look up 3. to check what the obvious answer was supposed to be). Obviously the machine-widget ratio hasn’t changed, and obviously exponential growth works like exponential growth.
When I see 1., however, I always think ‘oh it’s that bastard bat and ball question again, I know the correct answer but cannot see it’. And I have to stare at it for a minute or so to work it out, slowed down dramatically by the fact that Obvious Wrong Answer is jumping up and down trying to distract me.
I did a maths degree. I have a physics phd. This is not a hard question. Why does this happen?
I know I have a very intuition-heavy style of learning and doing maths. For the second two I have very strong cached intuitions that they map to, whereas I’m really lacking that for the first one for some reason. I mean, I can visualise a line 110 units long, and move another 100-unit line along it until there’s equal space at each end, but it’s not some natural thought for me.
Now, apparently:
The CRT was designed to assess a specific cognitive ability. It assesses individuals’ ability to suppress an intuitive and spontaneous (“system 1”) wrong answer in favor of a reflective and deliberative (“system 2”) right answer.
Yeah so that definitely isn’t getting tested for me. My System 2 hates maths and has no intention of putting in any effort on this test, but luckily System 1 has internalised the ‘intuitive and spontaneous’ answer for two of the questions for me. I will fail the first question unless my equally strong ‘the answer can’t be that obvious’ intuition fires, but that one makes me seriously worried about my answer to 3. as well.
My inability to internalise the bat and ball thing might be a quirk of my brain, but I’m sceptical of this test in general. It’s extremely vulnerable to having the right cached ideas.
Note: these posts are copied over from the ‘mathbucket’ section of my old tumblr blog and I haven’t put much effort into this, so there is likely to be context or formatting missing.
I thought it would be just duds from the back catalogue but they’ve put up loads of well-known texts at the undergrad and graduate level – particularly good for maths but some of the physics ones are also worth a look.
… and now for a pointless rant.
Why do so many maths textbooks insist on having this fucking boring introductory chapter that tells you a million preliminaries in incredibly terse prose? More symbols than words if you can possibly manage it? Like this:
I’m using Sachs and Wu’s General Relativity for Mathematicians as an example as that is the pdf I have open at the moment, but it’s not unusually bad, I could use anything really. And judging from the Preface this book is actually going to be pretty opinionated, with a distinctive writing style:
Many people believe that current physics and mathematics are, on balance, contributing usefully to the survival of mankind in a state of dignity. We disagree. But should humans survive, gazing at stars on a clear night will remain one of the things that make existence nontrivial.
That suggests a book that could be fun to read. Then it’s straight into exciting pages like this:
Who wants to read this stuff when they’ve just picked up a new book? It’s incredibly boring and does nothing to help me decide whether I’ll get anything out of the rest of the book. Why not, say, a basic example that illustrates something of what they want to cover? Or something interesting about the history of the subject? Or just a general overview of what’s coming up?
I’m sure there’s a reason I’m not getting, there usually is.
Do they want it to be self-contained? Well it’s still not self-contained, are they planning to teach me to count as well? It’s not the only book in the world anyway, surely I could just look at another book?
Do they want fix notation? That sounds a lot more reasonable, but surely they could just introduce the concepts in the context that they’re going to be used so that you actually remember them, with maybe a glossary of notation at the end?



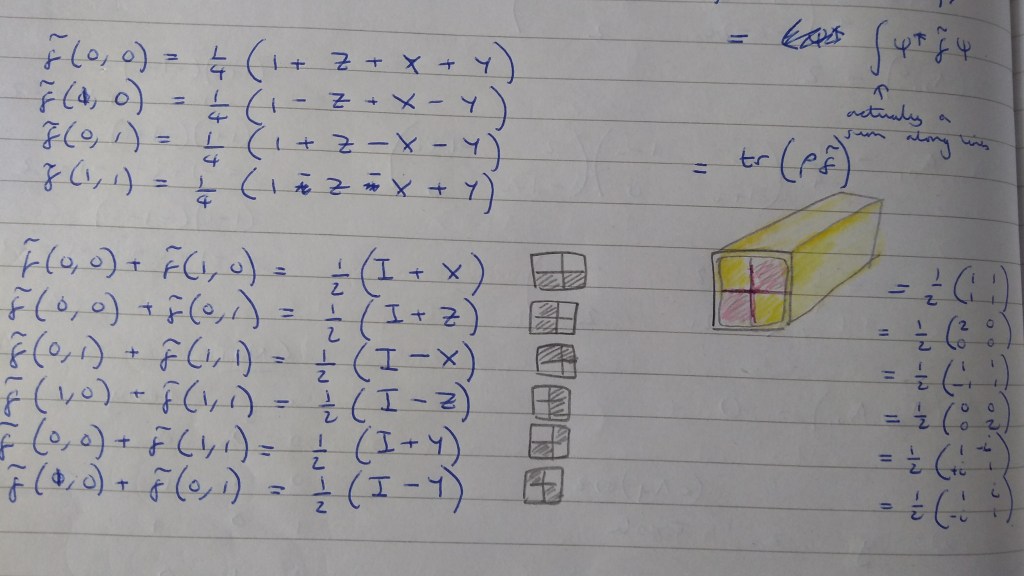
 to things, instead of
to things, instead of  . Why? No idea! It’s not like
. Why? No idea! It’s not like 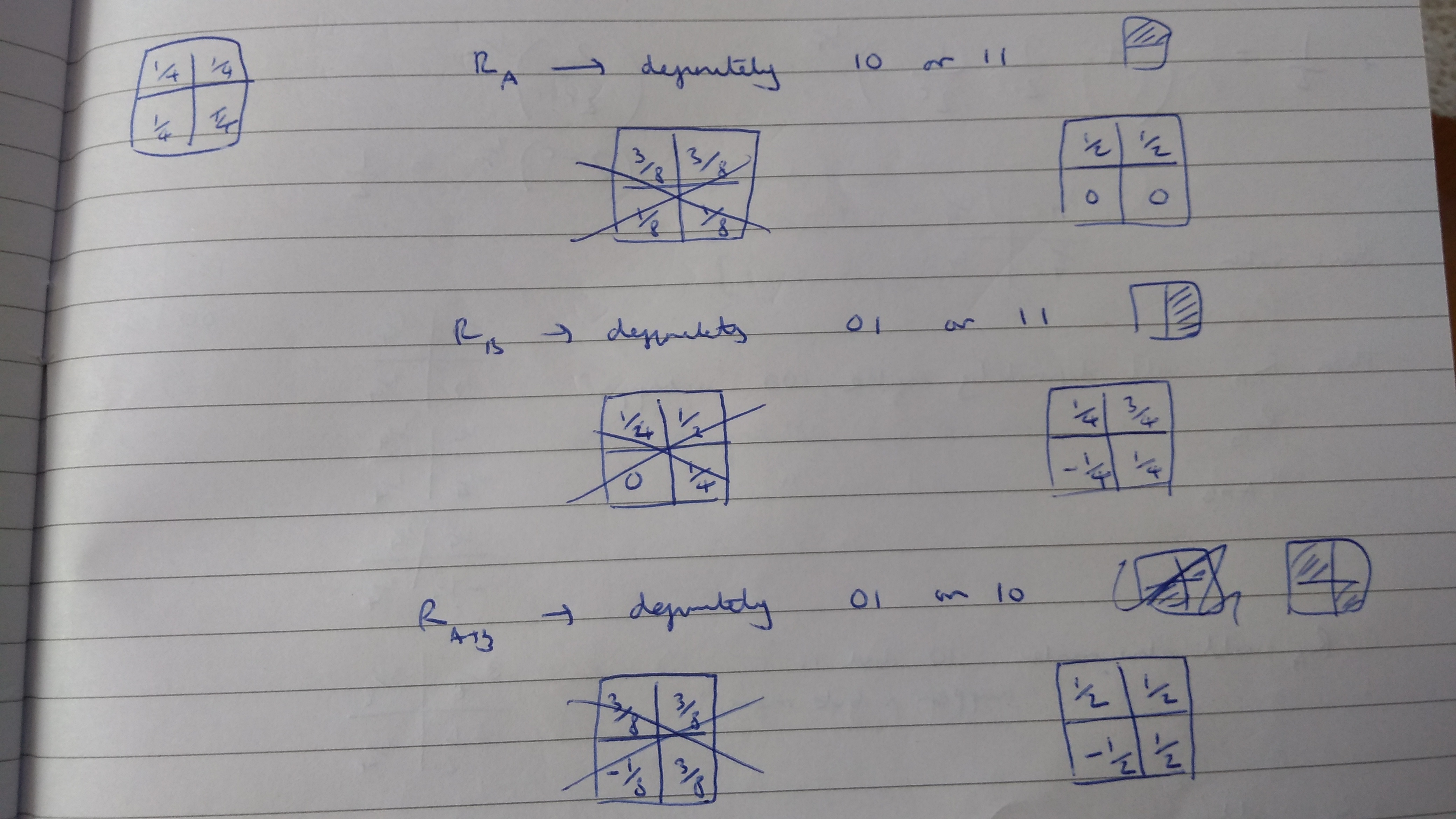


 to two decimal places without a calculator involves System 2 processes — mental operations requiring effort, motivation, concentration, and the execution of learned rules.
to two decimal places without a calculator involves System 2 processes — mental operations requiring effort, motivation, concentration, and the execution of learned rules.
 for the bat and
for the bat and  for the ball, we get the two equations
for the ball, we get the two equations ,
, ,
,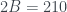 ,
, ,
,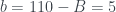 .
. for some reason and you have to find the answer by defined rules. Anyway, this is a separate rant.)
for some reason and you have to find the answer by defined rules. Anyway, this is a separate rant.)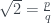 , a fraction expressed in its lowest terms, and rearrange it to get
, a fraction expressed in its lowest terms, and rearrange it to get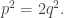
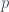 must be even, so you write it as
must be even, so you write it as 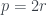 , sub it back in and notice that
, sub it back in and notice that  is going to have to be even too. But you started with the fraction expressed in its lowest terms, so the factors shouldn’t be there and you have a contradiction. Done.
is going to have to be even too. But you started with the fraction expressed in its lowest terms, so the factors shouldn’t be there and you have a contradiction. Done. as a product of its prime factors, e.g.
as a product of its prime factors, e.g.  . Then
. Then 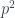 will have an even number of each prime factor, e.g.
will have an even number of each prime factor, e.g. 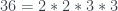 .
. is saying that an even set of prime factors equals another even set multiplied by a 2 on its own, which makes no sense at all.
is saying that an even set of prime factors equals another even set multiplied by a 2 on its own, which makes no sense at all.





![[source]](https://en.wikipedia.org/wiki/Bat_%26_Ball_railway_station#/media/File:Bat_%26_Ball_down_side_16-07-07.JPG){kind=link}