I’m over here anyway fixing some equation formatting that WordPress has decided to break, so I may as well call it. If I haven’t written anything here in over two years, and I only come here to fix broken things, it’s probably over.
I’m now writing Bucket Overflow instead over at Substack. Also I have a notebook blog, Notebucket, with shorter or lower effort pieces.
This is mainly a review of Brian Cantwell Smith’s latest book, The Promise of Artificial Intelligence: Reckoning and Judgment. But it’s also a second attempt to understand more of his overall project and worldview, after struggling through On the Origin of Objects a few years ago. I got a lot out of reading that, and wrote up what I did understand in my post on his idea of representations happening in the ‘middle distance’ between direct causal coupling and total irrelevance. But somehow the whole thing never cohered for me at the level I wanted to and I felt like I was missing something.
The new book is an easier read, but still not exactly straightforward. He’s telling an intricate story, and as with OOO the book is one single elegant arc of argument with little redundancy, so it’s not a forgiving format if you get lost. And I did get lost, in the sense that I’ve still got the ‘I’m missing something’ feeling. Part of the reason I’m posting in this on my ‘proper’ blog and not the notebucket is that I wanted the option of getting comments (this worked very well for the middle distance post and I got some extremely good ones). So if you can help me out with any of this, please do!
So, first, let’s explain the part that I do understand. The early part of the book is about the history of AI, and of course there’s been a whole lot more of this since OOO‘s publication in 1996. He divides this history into ‘first-wave’ GOFAI, with its emphasis on symbolic manipulation, and the currently successful ‘second wave’ of AI based on neural networks. There’s also a short ‘transition’ chapter on the 4E movement (’embodied, embedded, extended, enacted’) between the two waves, which he describes as important but not enough on its own, for reasons I’ll get into.
He’s mainly interested in what the first and second wave paradigms implicitly assume about the world. First-wave AI worked with logical inference on symbols that were supposed to directly map to discrete well-defined objects in the world. This assumes an ontology where that would actually work:
The ontology of the world is what I will call formal: discrete, well-defined, mesoscale objects exemplifying properties and standing in unambiguous relations.
And of course it mostly didn’t work, for most problems, because the world is mostly not like that.
Second-wave AI gets below these ready-made well-defined concepts to something more like the perceptual level. Objects aren’t baked in from the start but have to be recognised, distilled out of a gigantic soup of pixel-level data by searching for weak statistical correlations between huge numbers of variables. This has worked much better for tasks like image recognition and generation, suggesting that it captures something real about the complexity and richness of the world. Smith uses an analogy to a group of islands, where questions like ‘how many islands are there?’ depend on the level of detail you include:
Whether an outcropping warrants being called an island—whether it reaches “conceptual” height—is unlikely to have a determinate answer. In traditional philosophy such questions would be called vague, but I believe that label is almost completely inappropriate. Reality—both in the world and in these high-dimensional representations of it—is vastly richer and more detailed than can be “effably” captured in the idealized world of clear and distinct ideas.
There’s an interesting aside about how phenomenology has traditionally had a better grasp on this kind of richness than analytic philosophy, with its focus on logic and precision, which can mislead people into thinking it’s a subjective feature of our internal experience. Whereas really it’s about how the world is. Things are just too complicated to be fully captured by low-resolution logical systems:
That the world outstrips these schemes’ purview is a blunt metaphysical fact about the world — critical to any conceptions of reason and rationality worth their salt. Even if phenomenological philosophy has been more acutely aware of this richness than has the analytic tradition, the richness itself is a fundamental characteristic of the underlying unity of the metaphysics, not a uniquely phenomenological or subjective fact.
Smith would like to keep using the word ‘rationality’ for successful reasoning in general, not just the formal kind:
I want to reject the idea that intelligence and rationality are adequately modeled by something like formal logic, of the sort at which computers currently excel. That is: I reject any standard divide between “reason” as having no commitment, dedication, and robust engagement with the world, and emotion and affect as being the only locus of such “pro” action-oriented attitudes, on the other.
I haven’t decided whether I like this or not — I’ve kind of got used to David Chapman’s distinction between ‘reasonableness’ and ‘rationality’ so I’m feeling some resistance to using ‘rationality’ for the broader thing. At the least I still want a word for formal, systematic thinking.
OK, now we’re getting towards the bits I don’t understand so well. Smith doesn’t think that the resources of current ‘second-wave’ AI are going to be enough to reproduce anything like human thought. This is where the subtitle of the book, ‘Reckoning and Judgment’, comes in. First, here’s how he explains his use of ‘reckoning’:
… I use the term “reckoning” for the representation manipulation and other forms of intentionally and semantically interpretable behavior carried out by systems that are not themselves capable, in the full-blooded senses that we have been discussing, of understanding what it is that those representations are about—that are not themselves capable of holding the content of their representations to account, that do not authentically engage with the world’s being the way in which their representations represent it as being.
So, roughly, ‘reckoning’ refers to behaviour that can be understood intentionally but that isn’t itself produced by an intentional system. Current computers are capable of doing this kind of reckoning, but not the outward-facing participatory kind of thought he calls ‘judgment’:
I reserve the term “judgment,” in contrast, for the sort of understanding I have been talking about — the understanding that is capable of taking objects to be objects, that knows the difference between appearance and reality, that is existentially committed to its own existence and to the integrity of the world as world, that is beholden to objects and bound by them, that defers, and all the rest.
(‘Defers’ is another bit of his terminology — it means that the judging system knows that when the representation fails to match the world, it’s the world that should take precedence.)
This makes sense to me in broad strokes, but I still have the sense I had from OOO that I don’t really understand how much this is a high-level sketch and how much it’s supposed to use his specific ideas about representation.
This is where it might be useful to go back to his criticism of the 4E movement. This movement mostly focussed on the interaction of AI systems with their immediate environment, but this direct causal link is not enough. For example, take a computer interacting with a USB stick:
Surely, one might think, a computer can be oriented (or comport itself) toward a simple object, such as a USB stick. If I click a button that tells the computer to “copy the selected file to the USB stick in slot A”, and if in ordinary circumstances my so clicking causes the computer to do just that, can we not say that computer was oriented to the stick?
No, we cannot. Suppose that, just before the command is obeyed, a trickster plucks out the original USB stick and inserts theirs. The problem is not just that the computer would copy the file onto their stick without knowing the difference; it is that it does not have the capacity to distinguish the two cases, has no resources with which to comprehend the situation as different – cannot, that is, distinguish the description “what is in the drive” from the particular object that, at a given instant, satisfies that description.
This gets into Smith’s idea of representation as happening ‘in the middle distance’, not rigidly attached to the immediate situation like the computer is to the USB stick, and also not completely separate and irrelevant to it:
How could a computer know the difference between the stick and a description it satisfies (“the stick currently in the drive”), since at the moment of copying there need be no detectable physical difference in its proximal causal envelope between the two—and hence no way, at that moment, for the computer to detect the difference between the right stick and the wrong one? That is exactly what (normatively governed) representation systems are for: to hold systems accountable to, and via a vast network of social practices, to enable systems to behave appropriately toward, that which outstrips immediate causal coupling.
These ideas get folded in to his standards for ‘genuine intelligence’, along with several related capacities like being able to distinguish an object from representations of it, and care about the difference. This ability to ‘register’ an object is the key part of what he calls ‘judgment’ (‘the understanding that is capable of taking objects to be objects’).
So maybe I do understand this book after all, now that I’ve tried to write my thoughts down? Why do I still feel confused?
I think it’s the same disorientation I had with OOO, where I’m unsure when I’m reading a sketch of a detailed, specific mechanism and when I’m reading a more vision-level ‘insert future theory here’ thing. The middle distance idea is definitely a key part of his idea of judgment, and seems pretty specific, but then there are other vaguer parts about what the ability to take objects as objects would mean. And then, at the far end from concrete mechanism, judgment is also supposed to take on its ordinary language associations:
By judgment I mean that which is missing when we say that someone lacks judgment, in the sense of not fully considering the consequences and failing to uphold the highest principles of justice and humanity and the like. Judgment is something like phronesis, that is, involving wisdom, prudence, even virtue.
So the felt-sense feeling of confusion is something like an unsteadiness, an inability to pin down exactly how I’m supposed to be relating to this idea of judgment. I’m failing to successfully register it as an object, haha. I don’t know. I wish I could explain myself better ¯\_(ツ)_/¯
This is where some comments could be useful. If there’s anything specific that you think I’m missing, please let me know!
I’m pretty quiet on here currently. That’s because I have a different experiment going on instead: spamming out lots of short posts in one sitting on a notebook blog, Notebucket. I just realised I never linked to it from here, so… now I have.
The quality level is often low and it’s really not worth wading through all of those. But I’m pleased with some of them. Here are some of the more coherent and interesting ones:
Other than that, there’s a whole load of fragmented notes about some cluster of thoughts to do with Husserl, Derrida, mathematical notation as a technology… not sure exactly where I’m going with it, but I want to start combining it into more coherent blog posts soon, and posting them here again.
(Edit: AARGH!!! The WordPress editor gets more broken every time I try it, today it’s not even letting me preview my own post. I’m considering moving to Ghost eventually, which is where I host the notebook, but I need to sort out the commenting situation first. This is getting ridiculous though.)
The ‘research speedrun’ is a format that I’ve been playing with on here for the last year or so. It’s been more popular than I expected and it looks like there’s a lot more that could be done with the idea. So I thought I’d write it up here and see if anyone else wants to experiment with it themselves, or suggest different things to try.
The format
It’s a very simple format, so this section will be short:
Pick a topic
Set a one hour timer
Find out as much as possible about the topic before the buzzer goes off while writing up a live commentary
Do a very quick editing pass to fix the worst typos and then hit Publish
Obviously, there’s only so much you can learn in an hour – calling this ‘research’ is a little bit of a stretch. Sometimes I don’t even manage to leave Wikipedia! Even so, this technique works well for topics where the counterfactual is ‘I don’t read anything at all’ or ‘I google around aimlessly for half an hour and then forget it all’. Writing notes as I go means that I’m making enough active effort that I end up remembering some of it, but I know the process is timeboxed so it’s not going to end up being one of those annoying ever-expanding writing projects.
Here are a few rough categories of topics I’ve tried so far:
‘Sidequests’. Speedruns are great for topics that you find interesting but are never going to devote serious time to. I have a very minor side interest in the history of schools and universities, so if I come across something intriguing, like Renaissance abacus schools, it’s a good way to learn a few basic things quickly. I have one or two more ideas for speedruns in this area.
Historical background. An hour is quite a good length of time to pick up a few fragments of background historical context for something you’re interested in. One hour won’t get you far on its own, but the good thing about historical context is that it builds nicely over time as you get a better picture of the timeline of different events and how they affect each other.
Finding out what something is at a basic level. I did the ‘sensemaking’ speedrun because I’d heard that term a lot and had very little idea what it referred to.
Dubious or simplistic claims. The Prussian education system post was in this category. If you read pop pieces about education by people who don’t like school very much, there’s often a reference to ‘the Prussian education system’ as the source of all evils, maybe alongside a claim that it was set up to indoctrinate citizens into being good factory workers. If you’re starting with an understanding this simplistic you can improve it significantly within an hour. (The Prussian education system really did introduce many of the elements of modern compulsory schooling, but the factory workers bit doesn’t really hold up.)
Random curiosity. The Germaine de Staël one happened because I was reading Isaiah Berlin’s The Roots of Romanticism and she sounded like she might have had an interesting life (she did have an interesting life).
What I’ve got out of it
Sometimes the answer ends up being ‘not much’, but in that case I’ve only wasted an hour. I expect these to be pretty high variance. Some outcomes so far:
I discover that a topic is more interesting or important than I realised, and decide to spend more time on it. This happened with the Vygotsky Circle post – the actual speedrun was frustrating because I didn’t find any good quality sources about the intellectual scene, but I did realise Vygotsky himself was more interesting than I’d realised and ended up reading and makingnotes on his book Thought and Language.
I get good comments from more informed people and end up learning more after the speedrun as well. The sensemaking post was like this: in the speedrun itself I learned about the term’s origins in organisational studies, but not so much about the more recent online subculture that uses the term. After I posted it it ended up attracting a fair number of comments and twitter responses that explained the connection. (The root tweet is here, for people who have the patience to trawl through a branching twitter thread.)
I get exactly what I bargained for: an hour’s worth of basic knowledge about a topic I’m mildly interested in.
Another minor benefit is that I keep my writing habit going by producing something. This was actually pretty useful in the depths of winter lockdown apathy.
Other possibilities
My sense is that there’s a lot more that could be done with the format. Some potential ideas:
Party format: 5min everyone brainstorms topics of interest into a chat 1hr each person speedruns on one 1hr mini presentation from each person
I tried a tiny one with three people and it worked pretty well. I don’t love organising events and I doubt I’ll do this often myself, but if someone else wants to try it I’d probably be up for joining.
Chaining speedruns together. Multiple speedruns on the same topic would allow going into more depth while still having the ability to iterate every hour on exactly what you want to focus on.
Technical topics? I’m also interested in quantum foundations but I haven’t tried any maths- or physics-heavy speedrun topic yet. It sounds a lot harder, because that type of work tends to involve a lot more stopping and thinking, and maybe nothing would appear on the screen for long periods. Could still be worth trying.
Livestreamed speedruns. It could be funny to do an actual Twitch-style livestreamed speedrun. Or it could be atrociously dull. I’m not sure.
I’d like to hear suggestions for other ideas. I’d also be keen to hear from anyone who tries this as an experiment – please let me know how it goes!
This speedrun is a bit of an experiment and might go terribly. It’s a more open-ended topic than the ones I’ve tried before, and I’m not sure what I even want to know exactly.
The background is that I’m a big fan of Sarah Perry’s Tendrils of Mess in our Brains. This is a sketch of a satisfying theory of what mess is: interference from multiple conflicting ordering principles. (That’s probably too concise of a summary – see the post for more details and many good examples.)
I’d like to be able to contextualise this post, to have an idea about what other people have said about mess. Are there any other Big Theories of Mess? I’m not too sure where to start, even, but probably there is a Wikipedia article on mess. If not I’ll dredge Google Scholar. Let’s find out.
There is no Wikipedia article on mess 😦 Unless you’re looking for the military term.
Google Scholar is giving me articles written by people called Mess. This isn’t going well…
‘Theory of mess’ maybe? All sorts of things are coming up, mostly uninteresting. Maybe this paper on ‘Attuning to mess’? Oh it’s a book chapter, in some kind of military strategy context. Doesn’t look that promising for what I want.
This text is about mess, feelings of loneliness and loss, and their potential creative power. In a recent paper on collaborative writing, Wegener (2014) shares her experience with the reader on how a writing refuge almost turned into a prison. Having spent two days at the refuge, piles of papers with interview transcripts and field-notes were in a total mess. The themes in the writing seemed irrelevant and boring. Feeling lost, Wegener realised that she needed to break free and do something, and so she eventually decided to leave the research files behind and enjoy life in the sun outside the dirty windows in her room (Figure 10.1). She walked out along the beach and, when she came back, she began reading A. C. Bryatt’s A Biographer’s Tale, which she found by chance in her messy suitcase. The book was just meant to be a leisurely read and not intended to serve as a research tool and yet, soon, Wegener found herself writing a fictional dialogue with the protagonist Phineas from the tale about feeling lost and in need of creative inspiration (see also Chapter 8).
Getting warmer, still not really what I want.
Further down there’s a book called A Perfect Mess: The Hidden Benefits of Disorder, by Abrahamson and Freedman. The book preview looks kind of entertaining, but probably not going to get into any deep theory of mess. Hm, though I did just find this bit:
Mess Isn’t Necessarily an Absence of Order. Often a system is messy to some extent because of the lack of one specific type of order, even though other forms of order are present in abundance… What’s more, mess often arises from a failed order rather than from an absence of order.
This is sort of close to Perry’s thesis. But the book seems to be mostly more first-principles musings on mess, rather than helping me find more standard references. (Are there standard references? Where are the Established Theorists of Mess hanging out?)
There’s a categorisation of types of mess that may be worth returning to later, I’ll just add a screenshot in:
That’s probably all I’ll get out of this source for now. None of the other search results look useful. What about a general google search? Nope, totally useless, pages of dictionary definitions and other useless crap.
Hmm. This is not easy. It’s a mess, in fact. 41 minutes left, what to try next? Let’s search the Stanford Encyclopedia of Philosophy for the word ‘mess’. Nothing really about mess as such, just the word cropping up in various unrelated contexts. Where’s my Grand Theory of Mess??
OK I’ll go back to the original blog post and check for leads there. Oh OK there’s Alan Watts:
When you look at the clouds they are not symmetrical. They do not form fours and they do not come along in cubes, but you know at once that they are not a mess. A dirty old ashtray full of junk may be a mess but clouds do not look like that. When you look at the patterns of foam on water they never make an artistic mistake and they are not a mess. They are wiggly but in a way, orderly, although it is difficult for us to describe that kind of order.
Alan Watts, The Tao of Philosophy, p. 27.
I’ve always got some weird resistance to reading Alan Watts that I don’t fully understand but if this is the source I’d better go there. I don’t know though, I’m googling this quote and the context is sort of more first principles talking about mess. I’m still unclear what I do want but this isn’t really it. Ugh.
Back on Google Scholar looking up various combinations of ‘mess’ and ‘aesthetics’. Haha I just found a paper called ‘Chocolate or shit: aesthetics and cultural poverty in art therapy with children’. Not what I want either but… interesting I guess? I’m over half way through now and getting nowhere.
Hmm, this isn’t particularly promising but I just searched ‘theory of mess’ in google and found a review of something called Cooking with Mud: The Idea of Mess in Nineteenth-Century Art and Fiction by David Trotter. This at least seems to have some links to other works:
The only strange feature of this admirable book is its title. Baudelaire, the writer who pre-eminently characterized the creation of art in terms of the culinary and the cosmetic, described the metamorphosis of raw reality into crafted artefact, as the transformation of mud into gold, in a way which the anecdote from the childhood of Mary Butts, cited by David Trotter, barely encompasses. The sub-title of the book gives a far clearer picture of its range and content: the poetics and politics of “mess-theory” in Western fiction and painting, from approximately 1860 to 1900. “Mess” is to be understood in Samuel Beckett’s use of the term, in his 1961 interview with Tom Driver, when he spoke of seeking in art “a form that accommodates the mess.” Beckett, however, equated this activity with “chaos,” whereas Trotter, in his book, differentiates between the two. More precisely, Trotter makes a distinction between a theory of “waste” and a theory of “mess” (17). “Waste” is an effect which can be traced back to its cause and, ultimately, to human agency: it can be recycled and can be linked to renewal. Philosophically, in terms of order and disorder, it is related to determinism. By contrast, “mess” is governed by chance. It can be “good,” in that it may mark the beginning of an illusion (as in desire), or “bad,” in that it may mark the shattering of an illusion. It may be creative, as in the clutter of the studios of Edgar Degas or Francis Bacon, who each, in their different ways, produced some of their finest works in an environment of extreme “messiness.” Philosophically, it is linked to the concept of contingency and is, aesthetically, the harbinger of modernism.
But ‘mess’ as ‘governed by chance’ isn’t really what I’m looking for.
Now I’ve found a book called Making the Most of Mess by Emery Roe, which seems to be about policy and management. Quotes the Trotter piece: ‘Those interested in the role of mess in other fields should begin with mess theory in literary criticism (Trotter 2000), rubbish theory in anthropology (Thompson 1979), or the heap paradox in philosophy’.
I’m out of better ideas so let’s look up ‘rubbish theory in anthropology’. OK the book is Rubbish Theory: The Creation and Destruction of Value by Michael Thompson. Seems to be about waste and not particular about mess.
Oh god, 12 minutes left. Back on Scholar looking at stuff to do with mess and aesthetics. Debris, Mess and the Modernist Self? Making Sense of Mess. Marginal Lives, Impossible Spaces? This last one seems to theroise about mess at least a bit:
In the following few paragraphs I sketch some of the main concepts that animate our understanding of ‘mess’, as a way of attempting to outline a tradition of thinkers that were fascinated by lack of formal order, by chaos or filth; I hope then to draw a constellation of keywords which help us clarify the connotations of the term we intend to use as a guiding idea running throughout this issue.
In its comparative understanding, as the opposite or ‘lack’ of order, balance, and clarity, mess reminds us of the canonical Dionysian/Apollonian dialectic as famously articulated by Nietzsche’s The Birth of Tragedy (1872).
… Fast-forwarding to more recent times, it is noticeable that postmodern culture is certainly deeply fascinated by mess, by simultaneity and overlapping, by directionless hyperactivity and the overcrowded physical scenarios of mass society and conspicuous consumption.
Bla bla Lyotard, bla bla entropy. Doesn’t go too deep, seems to just be an introduction to a book of essays with a fairly typical pomo-ish inverting-the-order theme: ‘It also contributes, I believe, to questioning the rationale behind a value system that prioritizes order and rational organization of space, objects, and people.’
I just found another potentially interesting reference: Thomas Leddy, “Everyday Surface Aesthetic Qualities: ‘Neat,’ ‘Messy,’ ‘Clean,’ ‘Dirty,'” This is in something called ‘Everyday Aesthetics’ by Yuriko Saito. I’ve only found the first page of the Leddy so far and don’t have long left, and it looks like it probably won’t go deep on mess, though it might be worth reading anyway.
Ding! Ok, yeah, that did go pretty terribly. But my lack of success is least suggestive that there really isn’t a lot of deep theory of mess out there. There’s still a chance that I’m missing the right search terms, but I have no idea what the right ones would be. If you have any good ideas, let me know…
I’ve been getting interested in the Romantic movement recently. I’d started to dimly sense its enormous influence on later thought, but I had only a hazy idea of the details. So I picked up Isaiah Berlin’s The Roots of Romanticism to get a better understanding.
I chose this book in particular because I love Berlin’s style. The book was originally a series of lectures, given to an audience in Washington, DC in 1965 and broadcast to BBC radio. It’s not just a transcription, it’s been cleaned up to be more text-like, but still has an enjoyably conversational feel. I’m going to start with a couple of long quotes from the first chapter, ‘In Search of a Definition’, both to give a sense of that style and to set up the central question:
Suppose you were travelling about Western Europe, say in the 1820s, and suppose you spoke, in France, to the avant-garde young men who were friends of Victor Hugo, Hugolâtres. Suppose you went to Germany and spoke there to the people who had once been visited by Madame de Staël, who had interpreted the German soul to the French. Suppose you had met the Schlegel brothers, who were great theorists of romanticism, or one or two of the friends of Goethe in Weimar, such as the fabulist and poet Tieck, or other persons connected with the romantic movement, and their followers in the universities, students, young men, painters, sculptors, who were deeply influenced by the work of these poets, these dramatists, these critics. Suppose you had spoken in England to someone who had been influenced by, say, Coleridge, or above all by Byron – anyone influenced by Byron, whether in England or France or Italy, or beyond the Rhine, or beyond the Elbe.
These weird new scenes had a baffling mishmash of surface concerns — mysticism, poetry, folklore, free will — and the detailed content of any one scene often outright contradicted that of the others. But somehow at the base of it all was a correlated aesthetic sense:
Suppose you had spoken to these persons. You would have found that their ideal of life was approximately of the following kind. The values to which they attached the highest importance were such values as integrity, sincerity, readiness to sacrifice one’s life to some inner light, dedication to some ideal for which it is worth sacrificing all that one is, for which it is worth both living and dying. You would have found that they were not primarily interested in knowledge, or in the advance of science, not interested in political power, not interested in happiness, not interested, above all, in adjustment to life, in finding your place in society, in living at peace with your government, even in loyalty to your king, or to your republic. You would have found that common sense, moderation, was very far from their thoughts. You would have found that they believed in the necessity of fighting for your beliefs to the last breath in your body, and you would have found that they believed in the value of martyrdom as such, no matter what the martyrdom was martyrdom for. You would have found that they believed that minorities were more holy than majorities, that failure was nobler than success, which had something shoddy and something vulgar about it.
That’s not your father’s Enlightenment values. Where did all this come from? Is it just a loose cluster of attitudes to life, or does it hold together in some deeper way?
The Romantic bag of ideas
Understanding this better is not a purely academic exercise for me. This doesn’t feel like a dead movement that I’m learning about out of mild historical curiosity. The whole wider culture seems to be stuck in a pendulum swing towards romantic-inspired ideas. I’m reminded of a Slate Star Codex review of The Black Swan, which talks about the previous swing of the pendulum. Taleb’s book was published in 2007, during a wave of enthusiasm for New Atheism, cognitive biases, I Fucking Love Science and the like:
… it seems like the “moment” for books about rationality came and passed around 2010. Maybe it’s because the relevant science has slowed down – who is doing Kahneman-level work anymore? Maybe it’s because people spent about eight years seeing if knowing about cognitive biases made them more successful at anything, noticed it didn’t, and stopped caring. But reading The Black Swan really does feel like looking back to another era when the public briefly became enraptured by human rationality, and then, after learning a few cool principles, said “whatever” and moved on.
This is all passé now, irrationalism is in, and we’re all supposed to be trading meme stonks or something. (I started writing this at the peak of… whatever the GameStop thing was… and only just remembered to come back and finish it.) There’s a resurgence of fascination with mysticism, with conspiracy theories, with the ontology-blurring effects of psychedelics. This is all vaguely Romanticism-tinged, in the same way that the 2007 zeitgeist was Enlightenment-tinged. It looks suspiciously like we collectively had enough of the Enlightenment bag of ideas and automatically reached out for the other standard-issue bag of ideas that western philosophy has helpfully put within grabbing range.
I wanted to get a better idea of what’s in the bag. It’s not all awful, any more than the Enlightenment bag was awful. There are some deep and important ideas that aren’t in the Enlightenment bag, which is one of the things that makes it so compelling. But it’s not the sort of stuff I want to uncritically load my brain up with.
I don’t want to get too sidetracked into current issues, though. This post is just about taking a look at what’s in the bag. I’ll give a brief summary of some of the main preoccupations of the movement, at least as told by Berlin. I’ll finish with Berlin’s answer to the question of what ties these ideas together.
First, though, I’ve got a couple of reservations about this book which I want to flag before I start. The first is to do with the style. Berlin has this witty, urbane midcentury style which I love – I could read piles of this stuff. It’s not a romantic style at all… it’s not dry or technical either, there’s a bit of warmth to it, but it’s very controlled, there’s a bit of ironic distance, none of the GIANT OUTPOURING OF EMOTION I associate with romanticism. To be honest, I’m much more comfortable with this – I don’t quite get romanticism deep down – but it still makes me suspicious that someone who writes in this style is also going to not quite get it, and miss some of the point. Still, I’m actually willing to read this, and I probably would not read a whole load of romantic rhapsodising.
The second reservation is that I have no idea how accurate any of this is! These are popular talks, and Berlin hardly quotes any primary sources at all, and I certainly haven’t gone and looked any up. He’s an entertaining speaker, but it’s all a little bit too fluent, and I’m suspicious that the entertainment comes at the expense of getting the details correct.
With that massive disclaimer, let’s go on to look at the bag of ideas. Berlin covers the following:
Particularism: a fascination with specific details for their own sake, and a distrust of big abstract theories
Expressionism: works of art should express the nature of the artist, rather than communicate objective truths
The importance of the will and of imposing this will on the world through authentic expression, both on an an individual level and at the scale of nations
The grounding of knowledge in action, rather than disinterested inquiry
Emphasis on symbolism and mythic understanding
An understanding that ordered, rational knowledge only accounts for a small part of experience, and that there are huge murky unexplained depths beneath. Nostalgia and paranoia as hidden creatures in these depths.
I’ll go through these in turn.
Particularism and expressionism
Berlin starts by talking about early influences on romanticism. One key character in this section is someone I’d never heard of, Johann Georg Hamann. From what I can quickly make out from the Berlin book and his Wikipedia article he was mainly notable as a kind of superspreader of the ideas of his time. He introduced Rousseau’s work to Kant, translated Hume into German, influenced Goethe and Hegel. His own work was mostly fragmentary and unfinished, but a recurring theme was a deep suspicion of generalisations, concepts and categories:
What they left out, of necessity, because they were general, was that which was unique, that which was particular, that which was the specific property of this particular man, or this particular thing. And that alone was of interest, according to Hamann. If you wished to read a book, you were not interested in what this book had in common with many other books. If you looked at a picture, you did not wish to know what principles had gone into the making of this picture, principles which had also gone into the making of a thousand other pictures in a thousand other ages by a thousand different painters. You wished to react directly, to the specific message, to the specific reality, which looking at this picture, reading this book, speaking to this man, praying to this god would convey to you.
Hamann’s protégé Johann Herder shared this fascination with picturesque detail:
Herder is the father, the ancestor, of all those travellers, all those amateurs, who go round the world ferreting out all kinds of forgotten forms of life, delighting in everything that is peculiar, everything that is odd, everything that is native, everything that is untouched.
This led him towards an expressionist view of the nature of art. Enlightenment thinkers had expected theories of aesthetic beauty to converge on shared, objective properties of the artwork:
.. what everyone agreed about was that the value of a work of art consisted in the properties which it had, its being what it was – beautiful, symmetrical, shapely, whatever it might be. A silver bowl was beautiful because it was a beautiful bowl, because it had the properties of being beautiful, however that is defined. This had nothing to do with who made it, and it had nothing to do with why it was made.
For Herder, art instead expressed the idiosyncratic attitude towards life of the individual artist. There was no need for these individual attitudes to converge, and indeed the attitudes of different artists can be mutually contradictory. The important thing is for each artist to express their own nature to the fullest extent that they can.
Nationalism and the will
Herder applied these ideas at the group level as well as the individual. Groups of people enmeshed in a similar way of life would naturally share certain attitudes, and these would be reflected in their art:
If a folk song speaks to you, they said, it is because the people who made it were Germans like yourself, and they spoke to you, who belong with them in the same society; and because they were Germans they used particular nuances, they used particular successions of sounds, they used particular words which, being in some way connected, and swimming on the great tide of words and symbols and experience upon which all Germans swim, have something peculiar to say to certain persons which they cannot say to certain other persons. The Portuguese cannot understand the inwardness of a German song as a German can, and a German cannot understand the inwardness of a Portuguese song, and the very fact that there is such a thing as inwardness at all in these songs is an argument for supposing that these are not simply objects like objects in nature, which do not speak; they are artefacts, that is to say, something which a man has made for the purpose of communicating with another man.
This is a sort of nationalism, and influenced later, much more damaging kinds. Knowing what came later, it’s easy to read this as an argument for hereditary racial differences, but Herder’s version is a culturally transmitted gestalt:
Herder does not use the criterion of blood, and he does not use the criterion of race. He talks about the nation, but the German word Nation in the eighteenth century did not have the connotation of ‘nation’ in the nineteenth. He speaks of language as a bond, and he speaks of soil as a bond, and the thesis, roughly speaking, is this: That which people who belong to the same group have in common is more directly responsible for their being as they are than that which they have in common with others in other places. To wit, the way in which, let us say, a German rises and sits down, the way in which he dances, the way in which he legislates, his handwriting and his poetry and his music, the way in which he combs his hair and the way in which he philosophises all have some impalpable common gestalt.
Most importantly, Herder isn’t interested in demonstrating the superiority of any of these national groups. Berlin describes Herder rather endearingly as "the father, the ancestor, of all those travellers, all those amateurs, who go round the world ferreting out all kinds of forgotten forms of life, delighting in everything that is peculiar, everything that is odd, everything that is native, everything that is untouched":
Herder is one of those not very many thinkers in the world who really do absolutely adore things for being what they are, and do not condemn them for not being something else. For Herder everything is delightful. He is delighted by Babylon and he is delighted by Assyria, he is delighted by India and he is delighted by Egypt. He thinks well of the Greeks, he thinks well of the Middle Ages, he thinks well of the eighteenth century, he thinks well of almost everything except the immediate environment of his own time and place. If there is anything which Herder dislikes it is the elimination of one culture by another. He does not like Julius Caesar because Julius Caesar trampled on a lot of Asiatic cultures, and we shall now not know what the Cappadocians were really after. He does not like the Crusades, because the Crusades damaged the Byzantines, or the Arabs, and these cultures have every right to the richest and fullest self-expression, without the trampling feet of a lot of imperialist knights. He disliked every form of violence, coercion and the swallowing of one culture by another, because he wants everything to be what it is as much as it possibly can.
Unfortunately the next person to take up this idea of national identity was Johann Fichte. Fichte was a philosopher following in the tradition of Kant. Kant himself was very much not a romantic:
He disliked everything that was rhapsodical or confused in any respect. He liked logic and he liked rigour. He regarded those who objected to these qualities as simply mentally indolent. He said that logic and rigour were difficult exercises of the human mind, and that it was customary for those who found these things too difficult to invent objections of a different type.
Still, Kant influenced romantic thinking through his ideas on human freedom.
One of the propositions about which he was convinced was that every man as such is aware of the difference between, on the one hand, inclinations, desires, passions, which pull at him from outside, which are part of his emotional or sensitive or empirical nature; and on the other hand the notion of duty, of obligation to do what is right, which often came into conflict with desire for pleasure and with inclination.
In the case of Kant it became an obsessive central principle. Man is man, for Kant, only because he chooses. The difference between man and the rest of nature, whether animal or inanimate or vegetable, is that other things are under the law of causality, other things follow rigorously some kind of foreordained schema of cause and effect, whereas man is free to choose what he wishes.
Fichte had some variant on Kant’s ideas about freedom and the will – I’m unaware of the details but it certainly seems to involve getting very excited about it:
‘At the mere mention of the name freedom’, says Fichte, ‘my heart opens and flowers, while at the word necessity it contracts painfully.’
He combined his conception of freedom with Herder’s strand of nationalism to get a much more virulent, aggressive kind, involving the struggle of nations to become free:
Gradually, after Napoleon’s invasions and the general rise of nationalist sentiment in Germany, Fichte began thinking that perhaps what Herder said of human beings was true, that a man was made a man by other men, that a man was made a man by education, by language… So, gradually, he moved from the notion of the individual as an empirical human being in space to the notion of the individual as something larger, say a nation, say a class, say a sect. Once you move to that, then it becomes its business to act, it becomes its business to be free, and for a nation to be free means to be free of other nations, and if other nations obstruct it, it must make war…
So Fichte ends as a rabid German patriot and nationalist. If we are a free nation, if we are a great creator engaged upon creating those great values which in fact history has imposed upon us, because we happen not to have been corrupted by the great decadence which has fallen upon the Latin nations; if we happen to be younger, healthier, more vigorous than those decadent peoples (and here Francophobia emerges again) who are nothing but the debris of what was once no doubt a fine Roman civilisation – if that is what we are, then we must be free at the expense of no matter what, and therefore, since the world cannot be half slave and half free, we must conquer the others, and absorb them into our texture.
The grounding of knowledge in action
Fichte’s emphasis on action in the world also shows up in his view of knowledge:
Life does not begin with disinterested contemplation of nature or of objects. Life begins with action. Knowledge is an instrument, as afterwards William James and Bergson and many others were to repeat; knowledge is simply an instrument provided by nature for the purpose of effective life, of action; knowledge is knowing how to survive, knowing what to do, knowing how to be, knowing how to adapt things to our use, knowing, in other words, how to live (and what to do in order not to perish), in some unawakened, semi-instinctive fashion.
… Because I live in a certain way, things appear to me in a certain fashion: the world of a composer is different from the world of a butcher; the world of a man in the seventeenth century is different from the world of a man in the twelfth century. There may be certain things which are common, but there are more things, or more important things at any rate, which, for him, are not.
I like this a lot, and it’s fascinating to see an earlier version of ideas that crop up later in the Pragmatists and then also in Heidegger and Wittgenstein. It certainly adds important ideas that Enlightenment views of detached inquiry were missing. But then the world-spirit stuff starts coming in. It starts well, with a sort of Merleau-Ponty-like thing about being constrained by the body…
Fichte began by talking about individuals, then he asked himself what an individual was, how one could become a perfectly free individual. One obviously cannot become perfectly free so long as one is a three-dimensional object in space, because nature confines one in a thousand ways.
… but then quickly descends into whatever this is:
Therefore the only perfectly free being is something larger than man, it is something internal – although I cannot force my body, I can force my spirit. Spirit for Fichte is not the spirit of an individual man, but something which is common to many men, and it is common to many men because each individual spirit is imperfect, because it is to some extent hemmed in and confined by the particular body which it inhabits. But if you ask what pure spirit is, pure spirit is some kind of transcendent entity (rather like God), a central fire of which we are all individual sparks – a mystical notion which goes back at least to Boehme.
Symbolism
I wrote a short notebook post last year where I compared two types of symbolism: conventions like ‘red means stop’, which have been carefully pruned to have one and only one meaning, and ‘poetic’, ‘mythic’ symbolism like the medieval rose, with thick multilayered meanings.
I got this from McGilchrist’s The Master and His Emissary, but it turns out that he got it from The Roots of Romanticism and I didn’t notice at the time. Berlin lays out the same distinction. It’s this second, poetic type that’s important to the romantics:
Symbolism is central in all romantic thought: that has always been noticed by all critics of the movement. Let me try to make it as clear as I am able, although I do not claim to understand it entirely, because, as Schelling very rightly says, romanticism is truly a wild wood, a labyrinth in which the only guiding thread is the will and the mood of a poet….
There are two kinds of symbols, to put it at its very simplest. There are conventional symbols and symbols of a somewhat different kind. Conventional symbols offer no difficulty… Red and green traffic lights mean what they mean by convention.
… But there are obviously symbols not quite of this kind… if you ask, for example, in what sense a national flag waving in the wind, which arouses emotions in people’s breasts, is a symbol, or in what sense the Marseillaise is a symbol… the answer will be that what these things symbolise is literally not expressible in any other way.
This second type of symbol feels inexhaustible; the more shades of meaning you extricate, the more you find. This is why they preoccupied the romantics, who were fascinated by the abundance and surplus of the world.
Nostalgia and paranoia
Berlin then talks about how this inexhaustibility leads to ‘two quite interesting and obsessive phenomena which are then very present both in nineteenth- and in twentieth-century thought and feeling.’ The first is nostalgia, the yearning for past meaning slipping from our fingers:
The nostalgia is due to the fact that, since the infinite cannot be exhausted, and since we are seeking to embrace it, nothing that we do will ever satisfy us.
… Your relation to the universe is inexpressible. This is the agony, this is the problem. This is the unending Sehnsucht, this is the yearning, this is the reason why we must go to distant countries, this is why we seek for exotic examples, this is why we travel in the East and write novels about the past, this is why we indulge in all manner of fantasies.
Then there is a darker version of this obsession, where the deep submerged currents of the world are out to get us.
There is an optimistic version of romanticism in which what the romantics feel is that by going forward, by expanding our nature, by destroying the obstacles in our path, whatever they may be… we are liberating ourselves more and more and allowing our infinite nature to soar to greater and greater heights and become wider, deeper, freer, more vital, more like the divinity towards which it strives. But there is another, more pessimistic version of this, which obsesses the twentieth century to some extent. There is a notion that although we individuals seek to liberate ourselves, yet the universe is not to be tamed in this easy fashion. There is something behind, there is something in the dark depths of the unconscious, or of history; there is something, at any rate, not seized by us which frustrates our dearest wishes.
This paranoia shows up in attempts to understand the consequences of the French Revolution, where the world had avenged itself on all the Enlightenment bluechecks who had tried to tame it with reason:
… what the Revolution led everybody to suspect was that perhaps not enough was known: the doctrines of the French philosophes, which were supposedly a blueprint for the alteration of society in any desired direction, had in fact proved inadequate. Therefore, although the upper portion of human social life was visible – to economists, psychologists, moralists, writers, students, every kind of scholar and observer of the facts – that portion was merely the tip of some huge iceberg of which a vast section was sunk beneath the ocean. This invisible section had been taken for granted a little too blandly, and had therefore avenged itself by producing all kinds of exceedingly unexpected consequences.
This paranoia can inspire great art, or take ‘all kinds of other, sometimes much cruder, forms’:
It takes the form, for example, of looking for all kinds of conspiracies in history. People begin to think that perhaps history is formed by forces over which we have no control. Someone is at the back of it all: perhaps the Jesuits, perhaps the Jews, perhaps the Freemasons.
I said I wasn’t going to explicitly link any of this back to Current Year, but at this point the echoes are not subtle. I’ll move on quickly to the final section, where I talk about how Berlin ties these disparate ideas together.
Comfort with contradiction
I can’t resist quoting one more chunk from the introductory chapter, an inspired prose poem on the wild variety of Romantic life and thought:
It is extreme nature mysticism, and extreme anti-naturalist aestheticism. It is energy, force, will, life, étalage du moi; it is also self-torture, self-annihilation, suicide. It is the primitive, the unsophisticated, the bosom of nature, green fields, cow-bells, murmuring brooks, the infinite blue sky. No less, however, it is also dandyism, the desire to dress up, red waistcoats, green wigs, blue hair, which the followers of people like Gérard de Nerval wore in Paris at a certain period. It is the lobster which Nerval led about on a string in the streets of Paris. It is wild exhibitionism, eccentricity, it is the battle of Ernani, it is ennui, it is taedium vitae, it is the death of Sardanopolis, whether painted by Delacroix, or written about by Berlioz or Byron. It is the convulsion of great empires, wars, slaughter and the crashing of worlds.
It’s a lot of other things besides. (There’s like a page more of this on either side… I have to stop somewhere.) What’s the connection between them?
Berlin makes the case that it’s precisely this comfort with contradiction that’s new in Romantic thought. The Romantics are free from the oppressive need to make any sort of consistent global sense out of their experience, so they can layer together as many weird ideas as they like.
This is a huge departure from Enlightenment thought, which expected coherent theories:
There are three propositions, if we may boil it down to that, which are, as it were, the three legs upon which the whole Western tradition rested. They are not confined to the Enlightenment, although the Enlightenment offered a particular version of them, transformed them in a particular manner. The three principles are roughly these. First, that all genuine questions can be answered, that if a question cannot be answered it is not a question. We may not know what the answer is, but someone else will.
… The second proposition is that all these answers are knowable, that they can be discovered by means which can be learnt and taught to other persons…
… The third proposition is that all the answers must be compatible with one another, because, if they are not compatible, then chaos will result.
Viewed through this lens, the ideas of the previous section come together as a way of navigating life without any absolute set of rules to act as a guide. Particularism is popular because details matter more than unreliable theories. Expressivism, because the important thing is to make something personally meaningful from the fragments available to you. Action is vital because there is no ultimate theory detached from individual understanding, so everyone must navigate as well as they can from their current starting point, enmeshed in the local culture. Fixed axioms are unavailable, but symbols can still work as potent ordering principles, natural clustering points in the web of meanings. And paranoia is a natural response to the other, inconsistent strands that never be completely assimilated and that may come to harm you.
There is a collision here of what Hegel afterwards called ‘good with good’. It is due not to error, but to some kind of conflict of an unavoidable kind, of loose elements wandering about the earth, of values which cannot be reconciled. What matters is that people should dedicate themselves to these values with all that is in them.
This makes a lot of sense to me, but there are still things that I’m confused by. This inconsistent patchwork somehow had to be built on top of a Christian worldview, with all the ultimate grounding in God’s truth that that implies. This was some time before the deeper collapse of systems of meaning in the late nineteenth and early twentieth century, so I would expect some sort of counterbalancing pull towards coherence, and I didn’t get a sense of how that worked from Berlin’s book. I maybe got a glimpse of them with Fichte’s talk about the world-spirit as a transcendent entity, ‘a central fire of which we are all individual sparks’. So maybe there was some nod to consistency at this inaccessible universal level, but an understanding that individual people or nations couldn’t achieve it?
Thus all round, the intellectual lightships had broken from their moorings, and it was a then a new and trying experience. The present generation which has grown up in an open spiritual ocean, which has got used to it and has learned to swim for itself, will never know what it was to find the lights all drifting, the compasses all awry, and nothing left to steer by except the stars.
This comes from the historian and novelist James Anthony Froude, writing about his own crisis of faith. I was surprised to learn that this was in the 1840s, not say the 1890s. So at least some of the breakdown was happening quite early.
Of course, I’m relying on a secondary source, so another option is that Berlin was writing a long way into the process of fragmentation and so maybe he reads more of this into the Romantics than was actually there. Still, it does look like a lot of resources for navigating groundlessness were available in Western culture earlier than I realised. It makes sense that we’d be reaching for this bag of ideas in times as weird as these.
Note: This review started as a series of threenewsletterentries in a kind of lazy quotes-and-notes format. I wanted to have a more polished single post that I could refer back to, and that turned out to be more work than I expected. I ended up changing the structure quite a lot, shifting from following the chronological order of events to focusing more on major ideas of the movement, which has come at the expense of covering the people involved in as much detail. So if you’re really interested, and can stand a few weird tangents about Philip Pullman’s influences and the sinking of the Titanic, the newsletter versions could be worth a look too.
I’ve recently been reading Drawing Theories Apart: The Dispersion of Feynman Diagrams in Postwar Physics, by David Kaiser. Feynman diagrams combine my longstanding interest in physics with my current weird-interest-of-the-moment, text as a technology (this was also the background inspiration for my recent visual programming post). They aren’t exactly text, but they’re a formalised, repeatable type of diagram that follow a certain set of rules, so they’re definitely text-adjacent. I ended up getting more interested in the details of the physics than in the text-as-technology angle, so that’s going to be the main focus of this somewhat rambling review, but a few other topics will come up too.
Feynman diagrams turn out to be an interesting lens for looking at the history of physics. One obvious way to think of physics is as a set of theories, like ‘thermodynamics’, ‘electromagnetism’, ‘quantum mechanics’, and so on, each with a sort of axiomatic core that various consequences can be developed from. This fits certain parts of physics rather well – special relativity is a particularly good fit, for instance, with its neat conceptual core of a few simple postulates.
At the other end of the scale is something like fluid dynamics. In theory I suppose most people in fluid dynamics are looking at the consequences of one theory, the Navier-Stokes equations, but that’s a horribly complicated set of nonlinear equations that nobody can solve in general. So in reality fluid dynamics is splintered into a bunch of subdisciplines studying various regimes where different approximations can be made – I’m not an expert here but stuff like supersonic flow, boundary layers, high viscosity – and each one has its bag of techniques and set of canonical examples. Knowing about Navier-Stokes is pretty useless on its own, you’re also going to need the bag of techniques for your subfield to make any progress. So a history of fluid dynamics needs to largely be a history of these techniques.
Quantum field theory, where Feynman diagrams were first developed, is also heavy on bags of techniques. These are harder than postulates to transmit clearly through a textbook, you really have to see a lot of examples and work exercises and so on, so tacit knowledge transmitted by experts is especially important. Kaiser makes this point early on (my bolds):
Once we shift from a view of theoretical work as selecting between preformed theories, however, to theoretical work as the crafting and use of paper tools, tacit knowledge and craft skill need not seem so foreign. Thomas Kuhn raised a similar problem with his discussion of “exemplars”. Kuhn wrote that science students must work to master exemplars, or model problems, before they can tackle research problems on their own. The rules for solving such model problems and generalizing their application are almost never adequately conveyed via appeals to overarching general principles and rarely appear in sufficient form within published textbooks.
This focus on ‘paper tools’ is in the tradition of Bruno Latour’s work on ‘inscriptions’, and in fact the title of Kaiser’s book comes from Latour’s paper, Visualisation and Cognition: Drawing Things Together [pdf]. Latour talks about the way that complicated laboratory procedures need to be condensed down into marks on paper in order to communicate with other scientists:
Like these scholars, I was struck, in a study of a biology laboratory, by the way in which many aspects of laboratory practice could be ordered by looking not at the scientists’ brains (I was forbidden access!), at the cognitive structures (nothing special), nor at the paradigms (the same for thirty years), but at the transformation of rats and chemicals into paper… Instruments, for instance, were of various types, ages, and degrees of sophistication. Some were pieces of furniture, others filled large rooms, employed many technicians and took many weeks to run. But their end result, no matter the field, was always a small window through which one could read a very few signs from a rather poor repertoire (diagrams, blots, bands, columns). All these inscriptions, as I called them, were combinable, superimposable and could, with only a minimum of cleaning up, be integrated as figures in the text of the articles people were writing. Many of the intellectual feats I was asked to admire could be rephrased as soon as this activity of paper writing and inscription became the focus for analysis.
These inscriptions are transportable and recombinable by scientists in different locations (‘immutable mobiles’):
If you wish to go out of your way and come back heavily equipped so as to force others to go out of *their* ways, the main problem to solve is that of *mobilization*. You have to go and to come back *with* the “things” if your moves are not to be wasted. But the “things” have to be able to withstand the return trip without withering away. Further requirements: the “things” you gathered and displaced have to be presentable all at once to those you want to convince and who did not go there. In sum, you have to invent objects which have the properties of being *mobile* but also *immutable*, *presentable*, *readable* and *combinable* with one another.
Kaiser’s focus is instead on the ways that diagrams elude this easy transmissibility, and the background of tacit knowledge that they rely on: ‘drawing theories apart’ rather than ‘drawing things together’. Here’s a representative anecdote:
… in the summer of 1949, Enrico Fermi had complained that he was unable to make sense of one of Bethe’s own recent papers, and hence could not reproduce and extend Bethe’s calculations. Fermi and Bethe were both experts in the field in question, and they had worked closely together throughout the war years; they knew the territory and they knew each other quite well.
Also, of course, they were Fermi and Bethe! If they can’t do it, there isn’t much hope for the rest of us.
What Feynman diagrams are…
Before I go any further, it might be useful to give a rough indication of what Feynman diagrams are, and what it’s like to calculate with them. (Disclaimer before I attempt to do this: I only have a basic knowledge of this myself!) The idea is that they’re a notational device used to translate big ugly equations into something easier to manipulate. Unlike most popular science explanations, I’m going to risk putting some of these big ugly equations on the screen, but the details of them are not important. I just want to give an idea of how they’re translated into diagrams.
The examples I’m using come from some excellent notes on Solving Classical Field Equations, by Robert Helling. These notes make the point that Feynman diagrams can be used in many contexts, including in classical physics – they’re not a quantum-only thing. It makes more sense to think of them as applying to a particular kind of mathematical method, rather than to a type of physical theory as such. This method is a specific kind of perturbation theory, a general class of techniques where you make a rough (‘zeroth-order’) approximation to a calculation and then add on successive (‘first-order’, ‘second-order’, ‘third-order’…) correction terms. If all goes well, each correction term is smaller enough than the last that the whole thing converges, and you get a better and better approximation the more terms you include.
Now let’s see how the correction terms map to diagrams. Here’s the first order correction for Helling’s example, in standard equation form:
And here’s the corresponding diagram:
I’m not going to go into the details of the exact rules for translating from equation to diagram, but hopefully you can see some correspondences – the cubed term translates into three branches, for example. The full rules are in Helling’s paper.
At this point there isn’t a big difference between the equation and the diagram in terms of total effort to write down. But in perturbation theory, the higher the order you go to, the more hairy looking the correction terms get – they’re built up in a kind of recursive way from pieces of the lower-level correction terms, and this gets fiddly quickly. For example, here’s the third order correction term:
Ugh. At this point, you can probably see why you want to avoid having to write this thing down. In diagram form this term becomes:
This is a lot less mistake-prone than writing down the big pile of integrals, and the rules tell you exactly what diagrams need to be included, what number to put in front of each one, etc. This is a big improvement. And that becomes even more important in quantum electrodynamics, where the calculations are much more complicated than these example ones.
… sort of
Well, that’s one view of what Feynman diagrams are, at least. As the subtitle indicates, this book is about the dispersion of Feynman diagrams through physics. A large part of this is about geographical dispersion, as physicists taught the new techniques to colleagues around the world, and another part is about the dispersion of the methods through different fields, but the most interesting parts for me were about the dispersion of the meaning of diagrams.
These differences in meaning were there from the start. In the section above I described Feynman diagrams as a notational device for making a certain kind of calculation easier. This mirrors the view of Freeman Dyson, who was the first person to understand Feynman’s diagrammatic method and show its equivalence to the existing mathematical version. Dyson was apparently always very careful to start with the standard mathematics, and then show how the diagrams could replicate this.
None of this fits with how Feynman himself viewed the diagrams. For Feynman, the diagrams were a continuation of an idiosyncratic path he’d been pursuing for some time already, where he tried to remove fields from his models of physics and replace them with direct particle interactions. He saw the diagrams themselves as describing actual particle interactions occurring in spacetime, and considered them to take precedence over the mathematical description:
… Feynman believed fervently that the diagrams were more primary and more important than any derivation that they might be given. In fact, Feynman continued to avoid the question of derivation in his articles, lecture courses and correspondence… Nowhere in Feynman’s 1949 article on the diagrams, for example, were the diagrams’ specific features or their strict one-to-one correlations with specific mathematical expressions derived or justified from first principles. Instead, Feynman avowed unapologetically that “Since the result was easier to understand than the derivation, it was thought best to publish the results first in this paper.”
This split persisted as methods were taught more widely and eventually condensed into textbooks. Some physicists stuck with the mathematical-formalism-first approach, while others took Feynman’s view to an extreme:
James Bjorken and Sidney Drell began their twin textbooks on relativistic quantum mechanics and quantum field theory from 1964 and 1965 with the strong statement that “one may go so far as to adopt the extreme view that the full set of all Feynman graphs is the theory.” Though they quickly backed off this stance, they firmly stated their “conviction” that the diagrams and rules for calculating directly from them “may well outlive the elaborate mathematical structure” of canonical quantum field theory, which, they further opined, might “in time come to be viewed more as a superstructure than as a foundation.”
I’d never thought about this before, but this line of argument makes a fair bit of sense to me. This was a new field and the mathematical formalism was not actually very much older than Feynman’s diagrams. So everything was still in flux, and if the diagrams looked simpler than the formalism then maybe that looked like an indication to start there instead? I’d be interested now to learn a bit more of the history.
A third motivation also appeared at this point. The immediate postwar years were a time of enormous expansion in physics funding, especially in the US, and huge numbers of new students were entering the field. These students mostly needed to calculate practical things quickly, and conceptual niceties were not important. Feynman diagrams were relatively straightforward to learn compared to the underlying formalism, so a diagram-first route that got students calculating quickly became popular.
This pragmatic motivation is one reason that Kaiser’s focus on diagrams works so well, compared to a theory-first approach. Most practitioners were not even trying to teach and apply consistent theories:
… textbooks during the 1950s and 1960s routinely threw together techniques of mixed conceptual heritage, encouraging students to apply an approximation based on nonrelativistic potential scattering here, a lowest-order Feynman diagram there.
There wasn’t any need to, when the pragmatic approach was working so well. New experimental results were coming out all the time, and theorists were running to keep up, finding ways of adapting their techniques to solve new problems. There was more than enough work to keep everyone busy without needing to worry about the conceptual foundations.
There’s something kind of melancholy about reading about this period now. This was the golden age of a particular type of physics, which worked astonishingly well right up until it didn’t. Eventually the new experimental results ran dry, theory caught up, and it was no longer obvious how to proceed further with current techniques. Other fields continued to flourish – astronomy, condensed matter – but particle physics lost its distinctive cultural position at the leading edge of knowledge, and hasn’t regained it.
Still, I enjoyed the book, and I’m hoping it might end up helping me make some more sense of the physics, as well as the history. Since reading Helling’s notes on Feynman diagrams in classical physics, I’ve been curious about how they connect to the quantum versions. There’s a big difference between the classical and quantum diagrams – the quantum ones have loops and the classical ones don’t – and I’d like to understand why this happens at a deeper level, but it’s kind of hard to compare them properly when the formalisms used are so different. Knowing more about the historical development of the theory has given me some clues for where to to start from. I’m looking forward to exploring this more.
I’m starting to write up a review of Isaiah Berlin’s The Roots of Romanticism, and this quote fragment jumped out at me:
Suppose you went to Germany and spoke there to the people who had once been visited by Madame de Staël, who had interpreted the German soul to the French.
It’s a poetic turn of phrase, and I have just about enough mild curiosity to fancy doing a speedrun on her. Currently I know absolutely nothing. Maybe I’ll also expand it to the people she visited, if it turns out that she’s at the centre of some interesting intellectual circle.
I’m calling this one a slow speedrun because it’s too hot here and like most people in the UK I don’t have air conditioning, so I’m writing this with my feet in a tub of ice water as a poor substitute. It’ll still be an hour long, but I’ll take it easy and probably won’t get through as much as normal.
Full name Anne Louise Germaine de Staël-Holstein, commonly known as Madame de Staël. 1766 – 1817.
She was a voice of moderation in the French Revolution and the Napoleonic era up to the French Restoration.
Her intellectual collaboration with Benjamin Constant between 1794 and 1810 made them one of the most celebrated intellectual couples of their time.
OK I’ve never even heard of him. Open in new tab.
She discovered sooner than others the tyrannical character and designs of Napoleon.[5] For many years she lived as an exile – firstly during the Reign of Terror and later due to personal persecution by Napoleon.
In exile she became the centre of the Coppet group with her unrivalled network of contacts across Europe.
Ah, brilliant, there’s an intellectual scene, that’s what I was hoping for. Open in new tab.
In 1814 one of her contemporaries observed that "there are three great powers struggling against Napoleon for the soul of Europe: England, Russia, and Madame de Staël".
Nice. Now I understand the allusion in that Berlin quote.
Known as a witty and brilliant conversationalist, and often dressed in daring outfits, she stimulated the political and intellectual life of her times. Her works, whether novels, travel literature or polemics, which emphasised individuality and passion, made a lasting mark on European thought. De Staël spread the notion of Romanticism widely by its repeated use
OK, now for some historical background on her childhood. Only child of a popular Parisian salon host and a prominent banker and statesman. They both have wikipedia pages too but I doubt I’d get to them.
Mme Necker wanted her daughter educated according to the principles of Jean-Jacques Rousseau and endow her with the intellectual education and Calvinist discipline instilled in her by her pastor father.
Haha, poor child. Sounds like she turned out quite well given the circumstances.
At the age of 13, she read Montesquieu, Shakespeare, Rousseau and Dante.[10] This exposure probably contributed to a nervous breakdown in adolescence, but the seeds of a literary vocation had been sown.
Her father got into trouble by releasing the national budget, which had always been kept secret. So he got dismissed and they moved to a chateau on Lake Geneva. Then back to Paris once the fuss died down.
Aged 11, Germaine had suggested to her mother she marry Edward Gibbon, a visitor to her salon, whom she found most attractive. Then, she reasoned, he would always be around for her.[12] In 1783, at seventeen, she was courted by William Pitt the Younger and by the fop Comte de Guibert, whose conversation, she thought, was the most far-ranging, spirited and fertile she had ever known.
It’s very tempting to get sidetracked and read the article on fops, but let’s not. After this her parents got impatient and married her off to some Swedish diplomat.
On the whole, the marriage seems to have been workable for both parties, although neither seems to have had much affection for the other.
Now we’re getting to her actual work.
In 1788, de Staël published Letters on the works and character of J.J. Rousseau.[15] In this panegyric, written initially for a limited number of friends (in which she considered his housekeeper Thérèse Levasseur as unfaithful), she demonstrated evident talent, but little critical discernment.
OK, she was 22 at this point. Now there’s another argument between her father and the king and he gets dismissed and exiled.
In December 1788 her father persuaded the king to double the number of deputies at the Third Estate in order to gain enough support to raise taxes to defray the excessive costs of supporting the revolutionaries in America. This approach had serious repercussions on Necker’s reputation; he appeared to consider the Estates-General as a facility designed to help the administration rather than to reform government.[16] In an argument with the king, whose speech on 23 June he didn’t attend, Necker was dismissed and exiled on 11 July. On Sunday, 12 July the news became public and an angry Camille Desmoulins suggested storming the Bastille.[17]
Oh but it doesn’t last long:
On 16 July he was reappointed; Necker entered Versailles in triumph.
But then he resigned a couple of years later and moved to Switzerland. This is about the time that Germaine de Staël holds a salon.
The increasing disturbances caused by the Revolution made her privileges as the consort of an ambassador an important safeguard. Germaine held a salon in the Swedish embassy, where she gave "coalition dinners", which were frequented by moderates such as Talleyrand and De Narbonne, monarchists (Feuillants) such as Antoine Barnave, Charles Lameth and his brothers Alexandre and Théodore, the Comte de Clermont-Tonnerre, Pierre Victor, baron Malouet, the poet Abbé Delille, Thomas Jefferson, the one-legged Minister Plenipotentiary to France Gouverneur Morris, Paul Barras, a Jacobin (from the Plain) and the Girondin Condorcets.
That’s quite a list.
Lots of complicated revolutionary stuff after this, things got bad and she fled to Switzerland as well. Then went to England for a bit and caused a scandal:
In January 1793, she made a four-month visit to England to be with her then lover, the Comte de Narbonne at Juniper Hall. (Since 1 February France and Great Britain were at war.) Within a few weeks she was pregnant; it was apparently one of the reasons for the scandal she caused in England.
Back in Switzerland for a while, then she meets Benjamin Constant, then moves back to Paris with him.
In 1796 she published Sur l’influence des passions, in which she praised suicide, a book which attracted the attention of the German writers Schiller and Goethe.
Still absorbed by French politics, Germaine reopened her salon.[41] It was during these years that Mme de Staël arguably exerted most political influence.
More trouble, she leaves Paris for a bit. This is complicated. Then back again. I feel like I’m learning a lot about where she lived and not much about her ideas.
De Staël completed the initial part of her first most substantial contribution to political and constitutional theory, "Of present circumstances that can end the Revolution, and of the principles that must found the republic of France".
Now we’re getting in to her conflict with Napoleon.
On 6 December 1797 she had a first meeting with Napoleon Bonaparte in Talleyrand’s office and again on 3 January 1798 during a ball. She made it clear to him she did not agree with his planned French invasion of Switzerland. He ignored her opinions and would not read her letters.
and later:
He did not like her cultural determinism and generalizations, in which she stated that "an artist must be of his own time".[48][51] In his opinion a woman should stick to knitting.[52] He said about her, according to the Memoirs of Madame de Rémusat, that she "teaches people to think who had never thought before, or who had forgotten how to think".
Still running a salon but it’s getting dangerous. In 1803 Napoleon exiles her from Paris and she travels with Constant to Germany.
33 minutes left, I might have to speed up and not get bogged down in every detail. Though it looks like this is the interesting gbit She meets Goethe, Schiller and Schlegel. Her father dies and it looks like Coppet is the name of the place she’s inherited:
On 19 May she arrived in Coppet and found herself its wealthy and independent mistress, but her sorrow for her father was deep.
In July Constant wrote about her, "She exerts over everything around her a kind of inexplicable but real power. If only she could govern herself, she might have governed the world."
Next she visited Italy, wrote a book on it, Nopleon decided she was having too much fun and sent her back to Coppet.
Her house became, according to Stendhal, "the general headquarters of European thought" and was a debating club hostile to Napoleon, "turning conquered Europe into a parody of a feudal empire, with his own relatives in the roles of vassal states"
Some more travels in France and then Vienna. Benjamin Constant has also married someone else in the meantime, without telling her.
De Staël set to work on her book about Germany – in which she presented the idea of a state called "Germany" as a model of ethics and aesthetics and praised German literature and philosophy.[76] The exchange of ideas and literary and philosophical conversations with Goethe, Schiller, and Wieland had inspired de Staël to write one of the most influential books of the nineteenth century on Germany.
Yet more convoluted stuff where she gets back into France and then gets exiled again when she tries to publish the Germany book there.
She found consolation in a wounded veteran officer named Albert de Rocca, twenty-three years her junior, to whom she got privately engaged in 1811 but did not marry publicly until 1816.
I think I missed what happened to her first husband. It’s too hot to keep track of all this stuff.
Now there’s some complicated journey across eastern Europe to Russia. Then Sweden, then England.
She met Lord Byron, William Wilberforce, the abolitionist and Sir Humphry Davy, the chemist and inventor. According to Byron, "She preached English politics to the first of our English Whig politicians … preached politics no less to our Tory politicians the day after."[85] In March 1814 she invited Wilberforce for dinner and would devote the remaining years of her life to the fight for the abolition of the slave trade.
Returns to Paris yet again, where her salon is popular yet again, then fled to Coppet yet again. This is why I’m getting bogged down. Byron visited Coppet a lot.
"Byron was particularly critical of de Staël’s self-dramatizing tendencies"
haha.
One final trip to Paris:
Despite her increasing ill-health, she returned to Paris for the winter of 1816–17, living at 40, rue des Mathurins. Constant argued with de Staël, who had asked him to pay off his debts to her. A warm friendship sprang up between Madame de Staël and the Duke of Wellington, whom she had first met in 1814, and she used her influence with him to have the size of the Army of Occupation greatly reduced.[94]
She had become confined to her house, paralyzed since 21 February 1817. She died on 14 July 1817
So I’m finally through her biography. My god. She basically travelled everywhere and met everyone. I got tired reading this.
Oh I missed the bit about her novels somehow.
De Staël published a provocative, anti-Catholic novel Delphine, in which the femme incomprise (misunderstood woman) living in Paris between 1789 and 1792, is confronted with conservative ideas about divorce after the Concordat of 1801.
This is before Napoleon exiled her.
Right I have 18 minutes left, I think I’ll look up the Coppet group article. Oh boring, it’s just a couple of short paragraphs and a big list of names.
The Coppet group (Groupe de Coppet), also known as the Coppet circle, was an informal intellectual and literary gathering centred on Germaine de Staël during the time period between the establishment of the Napoleonic First Empire (1804) and the Bourbon Restoration of 1814-1815.[1][2][3][4] The name comes from Coppet Castle in Switzerland.
Core group: her family plus Humboldt, Schlegel and a bunch of names I dont’ recognise. Loong list of visitors, the ones I recognise from a quick skim are Byron, Clausewitz and Humphry Davy.
This doesn’t seem like a very tightly knit scene, too many people and too varied in their views. Maybe not as interesting as I was hoping for. Did a quick google and nothing is really standing out. Fine, let’s look up Benjamin Constant instead for the last ten minutes.
Henri-Benjamin Constant de Rebecque (French: [kɔ̃stɑ̃]; 25 October 1767 – 8 December 1830), or simply Benjamin Constant, was a Swiss-French political thinker, activist and writer on political theory and religion.
I’m sort of running out of energy now. It’s got hotter and this tub of ice water has warmed up. Something something proponent of classical liberalism, wrote some essays and pamphlets and so on. Skim for interesting bits.
Constant looked to Britain rather than to ancient Rome for a practical model of freedom in a large mercantile society. He drew a distinction between the "Liberty of the Ancients" and the "Liberty of the Moderns".
Ancients: parcipatory, burdensome, good for small homogeneous societies. Moderns: less direct participation, voters elect representativies.
He criticised several aspects of the French Revolution, and the failures of the social and political upheaval. He stated how the French attempted to apply ancient republican liberties to a modern state. Constant realized that freedom meant drawing a line between a person’s private life and that of state interference.[19] He praised the noble spirit of regenerating the state. However, he stated that it was naïve for writers to believe that two thousand years had not brought some changes in the customs and needs of the people.
Constant believed that, in the modern world, commerce was superior to war. He attacked Napoleon’s belligerence, on the grounds that it was illiberal and no longer suited to modern commercial social organization. Ancient Liberty tended to rely on war, whereas a state organized on the principles of Modern Liberty would tend to be at peace with all other peaceful nations.
Ah, nice link back to Berlin:
The British philosopher and historian of ideas, Sir Isaiah Berlin has acknowledged his debt to Constant.
Four minutes to go but I’ll end it there, I’m tired of this.
That worked ok apart from the bit where I got tired at the end. I feel like I learned a lot more about personal life and travels round Europe than I did about her ideas – would have been nice to understand more about the romanticism connection, exactly what ideas she picked up from Germany, etc. Still, she was interesting enough that that didn’t bother me too much.
I’m a fairly frequent Hacker News lurker, especially when I have some other important task that I’m avoiding. I normally head to the Active page (lots of comments, good for procrastination) and pick a nice long discussion thread to browse. So over time I’ve ended up with a good sense of what topics come up a lot. “The Bay Area is too expensive.” “There are too many JavaScript frameworks.” “Bootcamps: good or bad?” I have to admit that I enjoy these. There’s a comforting familiarity in reading the same internet argument over and over again.
One of the more interesting recurring topics is visual programming:
Visual Programming Doesn’t Suck. Or maybe it does? These kinds of arguments usually start with a few shallow rounds of yay/boo. But then often something more interesting happens. Some of the subthreads get into more substantive points, and people with a deep knowledge of the tool in question turn up, and at this point the discussion can become genuinely useful and interesting.
This is one of the things I genuinely appreciate about Hacker News. Most fields have a problem with ‘ghost knowledge’, hard-won practical understanding that is mostly passed on verbally between practitioners and not written down anywhere public. At least in programming some chunk of it makes it into forum posts. It’s normally hidden in the depths of big threads, but that’s better than nothing.
I decided to read a bunch of these visual programming threads and extract some of this folk wisdom into a more accessible form. The background for how I got myself into this is a bit convoluted. In the last year or so I’ve got interested in the development of writing as a technology. There are two books in particular that have inspired me:
Walter Ong’s Orality and Literacy: the Technologizing of the Word. This is about the history of writing and how it differs from speech; I wrote a sort of review here. Everything that we now consider obvious, like vowels, full stops and spaces between words, had to be invented at some point, and this book gives a high level overview of how this happened and why.
Catarina Dutilh Novaes’s Formal Languages in Logic. The title makes it sound like a maths textbook, but Novaes is a philosopher and really it’s much closer to Ong’s book in spirit, looking at formal languages as a type of writing and exploring how they differ from ordinary written language.
Dutilh Novaes focuses on formal logic, but I’m curious about formal and technical languages more generally: how do we use the properties of text in other fields of mathematics, or in programming? What is text good at, and what is it bad at? Comment threads on visual programming turn out to be a surprisingly good place to explore this question. If something’s easy in text but difficult in a specific visual programming tool, you can guarantee that someone will turn up to complain about it. Some of these complaints are fairly superficial, but some get into some fairly deep properties of text: linearity, information density, an alphabet of discrete symbols. And conversely, enthusiasm for a particular visual feature can be a good indicator of what text is poor at.
So that’s how I found myself plugging through a text file with 1304 comments pasted into it and wondering what the hell I had got myself into.
What I did
Note: This post is looong (around 9000 words), but also very modular. I’ve broken it into lots of subsections that can be read relatively independently, so it should be fairly easy to skip around without reading the whole thing. Also, a lot of the length is from liberal use of quotes from comment threads. So hopefully it’s not quite as as bad as it looks!
This is not supposed to be some careful scientific survey. I decided what to include and how to categorise the results based on whatever rough qualitative criteria seemed reasonable to me. The basic method, such as it was, was the following:
Type ‘visual programming’ into the HN search box and pull out the six entries on the first page that were a) about visual programming in general, not a specific tool and b) had long discussion threads (100+ comments). These six threads were:
Skim through the comments and do a rough triage, keeping anything that was on-topic and fairly substantive
Pull out interesting-looking parts of these comments into a spreadsheet, and tag with common themes that I noticed
Write this blog post
The basic structure of the rest of the post is the following:
A breakdown of what commenters normally meant by ‘visual programming’ in these threads. It’s a pretty broad term, and people come in with very different understandings of it.
Common themes. This is the main bulk of the post, where I’ve pulled out topics that came up in multiple threads.
A short discussion-type section with some initial questions that came to mind while writing this. There are many directions I could take this in, and this post is long enough without discussing these in detail, so I’ll just wave at some of them vaguely. Probably I’ll eventually write at least one follow-up post to pick up some of these strands when I’ve thought about them more.
Types of visual programming
There are also a lot of disparate visual programming paradigms that are all classed under “visual”, I guess in the same way that both Haskell and Java are “textual”. It makes for a weird debate when one party in a conversation is thinking about patch/wire dataflow languages as the primary VPLs (e.g. QuartzComposer) and the other one is thinking about procedural block languages (e.g. Scratch) as the primary VPLs.
One difficulty with interpreting these comments is that people often start arguing about ‘visual programming’ without first specifying what type of visual programming they mean. Sometimes this gets cleared up further into a comment thread, when people start naming specific tools, and sometimes it never gets cleared up at all. There were a few broad categories that came up frequently, so I’ll start by summarising them below.
There are a large number of visual programming tools that are roughly in the paradigm of ‘boxes with some arrows between them’, like the LabVIEW example above. I think the technical term for these is ‘node-based’, so that’s what I’ll call them. These ended up being the main topic of conversation in four of the six discussions, and mostly seemed to be the implied topic when someone was talking about ‘visual programming’ in general. Most of these tools are special-purpose ones that are mainly used in a specific domain. These domains came up repeatedly:Laboratory and industrial control. LabVIEW was the main tool discussed in this category. In fact it was probably the most commonly discussed tool of all, attracting its fair share of rants but also many defenders.
Game engines. Unreal Engine’s Blueprints was probably the second most common topic. This is a visual gameplay scripting system.
Music production. Max/MSP came up a lot as a tool for connecting and modifying audio clips.
Visual effects. Houdini, Nuke and Blender all have node-based editors for creating effects.
Data migration. SSIS was the main tool here, used for migrating and transforming Microsoft SQL Server data.
Other tools that got a few mentions include Simulink (Matlab-based environment for modelling dynamical systems), Grasshopper for Rhino3D (3D modelling), TouchDesigner (interactive art installations) and Azure Logic Apps (combining cloud services).
The only one of these I’ve used personally is SSIS, and I only have a basic level of knowledge of it.
This category includes environments like Scratch that convert some of the syntax of normal programming into coloured blocks that can be slotted together. These are often used as educational tools for new programmers, especially when teaching children.
This was probably the second most common thing people meant by ‘visual programming’, though there was some argument about whether they should count, as they mainly reproduce the conventions of normal text-based programming:
Scratch is a snap-together UI for traditional code. Just because the programming text is embedded inside draggable blocks doesn’t make it a visual language, its a different UI for a text editor. Sure, its visual, but it doesn’t actually change the language at all in any way. It could be just as easily represented as text, the semantics are the same. Its a more beginner-friendly mouse-centric IDE basically.
Drag-n-drop UI builders came up a bit, though not as much as I originally expected, and generally not naming any specific tool (Delphi did get a couple of mentions.) In particular there was very little discussion of the new crop of no-code/low-code tools, I think because most of these threads predate the current hype wave.
These tools are definitely visual, but not necessarily very programmatic — they are often intended for making one specific layout rather than a dynamic range of layouts. And the visual side of UI design tends to run into conflict with the ability to specify dynamic behaviour:
The main challenge in this particular domain is describing what is supposed to happen to the layout when the size of the window changes, or if there are dependencies among visual elements (e.g. some element only appears when a check box is checked). When laying things out visually you can only ever design one particular instance of a layout. If all your elements are static, this works just fine. But if the layout is in any way dynamic (with window resizing being the most common case) you now have to either describe what you want to have happen when things change, or have the system guess. And there are a lot of options: scaling, cropping, letterboxing, overflowing, “smart” reflow… The possibilities are endless, so describing all of that complexity in general requires a full programming language. This is one the reasons that even CSS can be very frustrating, and people often resort to Javascript to get their UI to do the Right Thing.
These tools also have less of the discretised, structured element that is usually associated with programming — for example, node-based tools still have a discrete ‘grammar’ of allowable box and arrow states that can be composed together. UI tools are relatively continuous and unstructured, where UI elements can be resized to arbitrary pixel sizes.
Spreadsheets
There’s a good argument for spreadsheets being a visual programming paradigm, and a very successful one:
I think spreadsheets also qualify as visual programming languages, because they’re two-dimensional and grid based in a way that one-dimensional textual programming languages aren’t.
The grid enables them to use relative and absolute 2D addressing, so you can copy and paste formulae between cells, so they’re reusable and relocatable. And you can enter addresses and operands by pointing and clicking and dragging, instead of (or as well as) typing text.
Spreadsheets are definitely not the canonical example anyone has in mind when talking about ‘visual programming’, though, and discussion of spreadsheets was confined to a few subthreads.
Visual enhancements of text-based code
As a believer myself, I think the problem is that visual programming suffers the same problem known as the curse of Artificial Intelligence:
“As soon as a problem in AI is solved, it is no longer considered AI because we know how it works.” [1]
Similarly, as soon as a successful visual interactive feature (be it syntax highlighting, trace inspectors for step-by-step debugging, “intellisense” code completion…) gets adopted by IDEs and become mainstream, it is no longer considered “visual” but an integral and inevitable part of classic “textual programming”.
There were several discussions of visual tooling for understanding normal text-based programs better, through debugging traces, dependency graphs, inheritance hierarchies, etc. Again, these were mostly confined to a few subthreads rather than being a central example of ‘visual programming’.
Several people also pointed out that even text-based programming in a plain text file has a number of visual elements. Code as written by humans is not a linear string of bytes, we make use of indentation and whitespace and visually distinctive characters:
Code is always written with “indentation” and other things that demonstrate that the 2d canvas distribution of the glyphs you’re expressing actually does matter for the human element. You’re almost writing ASCII art. The ( ) and [ ] are even in there to evoke other visual types. — nikki93
Brackets are a nice example — they curve towards the text they are enclosing, reinforcing the semantic meaning in a visual way.
Experimental or speculative interfaces
At the other end of the scale from brackets and indentation, we have completely new and experimental visual interfaces. Bret Victor’s Dynamicland and other experiments were often brought up here, along with speculations on the possibilities opened up by VR:
As long as we’re speculating: I kind of dream that maybe we’ll see programming environments that take advantage of VR.
Humans are really good at remembering spaces. (“Describe for me your childhood bedroom.” or “What did your third grade teacher look like?”)
There’s already the idea of “memory palaces” [1] suggesting you can take advantage of spatial memory for other purposes.
I wonder, what would it be like to learn or search a codebase by walking through it and looking around?
This is the most exciting category, but it’s so wide open and untested that it’s hard to say anything very specific. So, again, this was mainly discussed in tangential subthreads.
Common themes
There were many talking points that recurred again and again over the six threads. I’ve tried to collect them here.
I’ve ordered them in rough order of depth, starting with complaints about visual programming that could probably be addressed with better tooling and then moving towards more fundamental issues that engage with the specific properties of text as a medium (there’s plenty of overlap between these categories, it’s only a rough grouping). Then there’s a grab bag of interesting remarks that didn’t really fit into any category at the end.
Missing tooling
A large number of complaints in all threads were about poor tooling. As a default format, text has an enormous ecosystem of existing tools for input, search, diffing, formatting, etc etc. Most of these could presumably be replicated for any given visual format, but there are many kinds of visual formats and generally these are missing at least some of the conveniences programmers expect. I’ve discussed some of the most common ones below.
Unreal has a VPL and it is a pain to use. A simple piece of code takes up so much desktop real estate that you either have to slowly move around to see it all or have to add more monitors to your setup to see it all. You think spaghetti code is bad imagine actually having a visual representation of it you have to work with. Organization doesn’t exist you can go left, up, right, or down.
The standard counterargument to this was that LabVIEW and most other node-based environments do come with tools for encapsulation: you can generally ‘box up’ sets of nodes into named function-like subdiagrams. The extreme types of spaghetti code are mostly produced by inexperienced users with a poor understanding of the modularisation options available to them, in the same way that a beginner Python programmer with no previous coding experience might write one giant script with no functions:
Somehow people form the opinion that once you start programming in a visual language that you’re suddenly forced, by some unknown force, to start throwing everything into a single diagram without realizing that they separate their text-based programs into 10s, 100s, and even 1000s of files.
Poorly modularized and architected code is just that, no matter the paradigm. And yes, there are a lot of bad LabVIEW programs out there written by people new to the language or undisciplined in their craft, but the same holds true for stuff like Python or anything else that has a low barrier to entry.
Viewed through this lens there’s almost an argument that visual spaghetti is a feature not a bug — at least you can directly see that you’ve created a horrible mess, without having to be much of a programming expert.
There were a few more sophisticated arguments against node-based editors that acknowledged the fact that encapsulation existed but still found the mechanics of clicking through layers of subdiagrams to be annoying or confusing.
It may be that I’m just not a visual person, but I’m currently working on a project that has a large visual component in Pentaho Data Integrator (a visual ETL tool). The top level is a pretty simple picture of six boxes in a pipeline, but as you drill down into the components the complexity just explodes, and it’s really easy to get lost. If you have a good 3-D spatial awareness it might be better, but I’ve started printing screenshots and laying them out on the floor. I’m really not a visual person though…
IDEs for text-based languages normally have features like code folding and call hierarchies for moving between levels, but these conventions are less developed in node-based tools. This may be just because these tools are more niche and have had less development time, or it may genuinely be a more difficult problem for a 2D layout — I don’t know enough about the details to tell.
Input
In general, all the dragging quickly becomes annoying. As a trained programmer, you can type faster than you can move your mouse around. You have an algorithm clear in your head, but by the time you’ve assembled it half-way on the screen, you already want to give up and go do something else.
Text-based languages also have a highly-refined interface for writing the language — most of us have a great big rectangle sitting on our desks with a whole grid of individual keys mapping to specific characters. In comparison, a visual tool based on a different paradigm won’t have a special input device, so it will have either have to rely on the mouse (lots of tedious RSI-inducing clicking around) or involve learning a new set of special-purpose keyboard shortcuts. These shortcuts can work well for experienced programmers:
If you are a very experienced programmer, you program LabVIEW (one of the major visual languages) almost exclusively with the keyboard (QuickDrop).
Let me show you an example (gif) I press “Ctrl + space” to open QuickDrop, type “irf” (a short cut I defined myself) and Enter, and this automatically drops a code snippet that creates a data structure for an image, and reads an image file.
Another tedious feature of many node-based tools is arranging all the boxes and arrows neatly on the screen. It’s irrelevant for the program output, but makes a big difference to readability. (Also it’s just downright annoying if the lines look wrong — my main memory of SSIS is endless tweaking to get the arrows lined up nicely).
Text-based languages are more forgiving, and also people tend to solve the problem with autoformatters. I don’t have a good understanding of why these aren’t common in node-based editors. (Maybe they actually are and people were complaining about the tools that are missing them? Or maybe the sort of formatting that is useful is just not automatable, e.g. grouping boxes by semantic meaning). It’s definitely a harder problem than formatting text, but there was some argument about exactly how hard it is to get at least a reasonable solution:
Automatic layout is hard? Yes, an optimal solution to graph layout is NP-complete, but so is register allocation, and my compiler still works (and that isn’t even its bottleneck). There’s plenty of cheap approximations that are 99% as good.
Same story again — text comes with a large ecosystem of existing tools for diffing, version control and code review. It sounds like at least the more developed environments like LabVIEW have some kind of diff tool, and an experienced team can build custom tools on top of that:
We used Perforce. So a custom tool was integrated into Perforce’s visual tool such that you could right-click a changelist and submit it for code review. The changelist would be shelved, and then LabVIEW’s diff tool (lvcompare.exe) would be used to create screenshots of all the changes (actually, some custom tools may have done this in tandem with or as a replacement of the diff tool). These screenshots, with a before and after comparison, were uploaded to a code review web server (I forgot the tool used), where comments could be made on the code. You could even annotate the screenshots with little rectangles that highlighted what a comment was referring to. Once the comments were resolved, the code would be submitted and the changelist number logged with the review. This is based off of memory, so some details may be wrong.
This is important because it shows that such things can exist. So the common complaint is more about people forgetting that text-based code review tools originally didn’t exist and were built. It’s just that the visual ones need to be built and/or improved.
Opinions were split on debugging. Visual, flow-based languages can make it easy to see exactly which route through the code is activated:
Debugging in unreal is also really cool. The “code paths” light up when activated, so it’s really easy to see exactly which branches of code are and aren’t being run – and that’s without actually using a debugger. Side note – it would be awesome if the lines of text in my IDE lit up as they were run. Also, debugging games is just incredibly fun and sometimes leads to new mechanics.
I remember this being about the only enjoyable feature of my brief time working with SSIS — boxes lit up green if everything went to plan, and red if they hit an exception. It was satisfying getting a nice run of green boxes once a bug was fixed.
On the other hand, there were problems with complexity again. Here are some complaints about LabVIEW debugging:
3) debugging is a pain. LabVIEW’s trace is lovely if you have a simple mathematical function or something, but the animation is slow and it’s not easy to check why the value at iteration 1582 is incorrect. Nor can you print anything out, so you end up putting an debugging array output on the front panel and scrolling through it.
4) debugging more than about three levels deep is painful: it’s slow and you’re constantly moving between windows as you step through, and there’s no good way to figure out why the 20th value in the leaf node’s array is wrong on the 15th iteration, and you still can’t print anything, but you can’t use an output array, either, because it’s a sub-VI and it’s going to take forever to step through 15 calls through the hierarchy.
There was a lot of discussion on what sort of problem domains are suited to ‘visual programming’ (which often turned out to mean node-based programming specifically, but not always).
Better for data flow than control flow
A common assertion was that node-based programming is best suited to data flow situations, where a big pile of data is tipped into some kind of pipeline that transforms it into a different form. Migration between databases would be a good example of this. On the other hand, domains with lots of branching control flow were often held to be difficult to work with. Here’s a representative quote:
Control flow is hard to describe visually. Think about how often we write conditions and loops.
That said – working with data is an area that lends itself well to visual programming. Data pipelines don’t have branching control flow and So you’ll see some really successful companies in this space.
I’m not sure how true this is? There wasn’t much discussion of why this would be the case, and it seems that LabVIEW for example has decent functionality for loops and conditions:
Aren’t conditionals and loops easier in visual languages? If you need something to iterate, you just draw a for loop around it. If you need two while loops each doing something concurrently, you just draw two parallel while loops. If you need to conditionally do something, just draw a conditional structure and put code in each condition.
One type of control structure I have not seen a good implementation of is pattern matching. But that doesn’t mean it can’t exist, and it’s also something most text-based languages don’t do anyway.
Looking at someexamples, these don’t look too bad.
Maybe the issue is that there is a conceptual tension between data flow and control flow situations themselves, rather than just the representation of them? Data flow pipelines often involve multiple pieces of data going through the pipeline at once and getting processed concurrently, rather than sequentially. At least one comment addressed this directly:
One of the unappreciated facets of visual languages is precisely the dichotomy between easy dataflow vs easy control flow. Everyone can agree that
–> [A] –> [B] –>
——>
represents (1) a simple pipeline (function composition) and (2) a sort of local no-op, but what about more complex representations? Does parallel composition of arrows and boxes represent multiple data inputs/outputs/computations occurring concurrently, or entry/exit points and alternative choices in a sequential process? Is there a natural “split” of flowlines to represent duplication of data, or instead a natural “merge” for converging control flows after a choice? Do looping diagrams represent variable unification and inference of a fixpoint, or the simpler case of a computation recursing on itself, with control jumping back to an earlier point in the program with updated data?
Overall I’d have to learn a fair bit more to understand what the problem is.
Accessible to non-programmers
Less controversially, visual tools are definitely useful for people with little programming experience, as a way to get started without navigating piles of intimidating syntax.
So the value ends up being in giving more people who are unskilled or less skilled in programming a way to express “programmatic thinking” and algorithms.
I have taught dozens of kids scratch and that’s a great application that makes programming accessible to “more” kids.
Visual programming is, unsurprisingly, well-suited to tasks that have a strong visual component. We see this on the small scale with things like colour pickers, which are far more helpful for choosing a colour than typing in an RGB code and hoping for the best. So even primarily text-based tools might throw in some visual features for tasks that are just easier that way.
Some domains, like visual effects, are so reliant on being able to see what you’re doing that visual tools are a no-brainer. See the TouchDesigner tutorial mentioned in this comment for an impressive example. If you need to do a lot of visual manipulation, giving up the advantages of text is a reasonable trade:
Why is plain text so important? Well for starters it powers version control and cut and pasting to share code, which are the basis of collaboration, and collaboration is how we’re able to construct such complex systems. So why then don’t any of the other apps use plain text if it’s so useful? Well 100% of those apps have already given up the advantages of plain text for tangential reasons, e.g., turning knobs on a synth, building a model, or editing a photo are all terrible tasks for plain text.
A related point was that visual tools are generally designed for niche domains, and rarely get co-opted for more general programming. A common claim was that visual tools favour concrete situations over abstract ones:
There is a huge difference between direct manipulation of concrete concepts, and graphical manipulation of abstract code. Visual programming works much better with the former than the latter.
It does seem to be the case that visual tools generally ‘stay close to the phenomena’. There’s a tension between between showing a concrete example of a particular situation, and being able to go up to a higher level of abstraction and dynamically generate many different examples. (A similar point came up in the section on drag-n-drop editors above.)
Deeper structural properties of text
“Text is the most socially useful communication technology. It works well in 1:1, 1:N, and M:N modes. It can be indexed and searched efficiently, even by hand. It can be translated. It can be produced and consumed at variable speeds. It is asynchronous. It can be compared, diffed, clustered, corrected, summarized and filtered algorithmically. It permits multiparty editing. It permits branching conversations, lurking, annotation, quoting, reviewing, summarizing, structured responses, exegesis, even fan fic. The breadth, scale and depth of ways people use text is unmatched by anything. There is no equivalent in any other communication technology for the social, communicative, cognitive and reflective complexity of a library full of books or an internet full of postings. Nothing else comes close.”
In this section I’ll look at properties that apply more specifically to text. Not everything in the quote above came up in discussion (and much of it is applicable to ordinary language more than to programming languages), but it does give an idea of the special position held by text.
Communicative ability
I think the reason is that text is already a highly optimized visual way to represent information. It started with cave paintings and evolved to what it is now.
“Please go to the supermarket and get two bottles of beer. If you see Joe, tell him we are having a party in my house at 6 tomorrow.”
It took me a few seconds to write that. Imagine I had to paint it.
The communicative range of text came up a few times. I’m not convinced on this one. It’s true that ordinary language has this ability to finely articulate incredibly specific meanings, in a way that pictures can’t match. But the real reference class we want to compare to is text-based programming, not ordinary language. Programming languages have a much more restrictive set of keywords that communicate a much smaller set of ideas, mostly to do with quantity, logical implication and control flow.
In the supermarket example above, the if-then structure could be expressed in these keywords, but all the rest of the work would be being done by tokens like “bottlesOfBeer”, which are meaningless to the computer and only help the human reading it.
As soon as we’ve assigned something a variable name, we’ve already altered our code into a form to assist our cognition.
It seems much more reasonable that this limited structure of keywords can be ported to a visual language, and in fact a node-based tool like LabVIEW seems to have most of them. Visual languages generally still have the ability to label individual items with text, so you can still have a “bottlesOfBeer” label if you want and get the communicative benefit of language. (It is true that a completely text-free language would be a pain to deal with, but nobody seems to be doing that anyway.)
Information density
A more convincing related point is that text takes up very little space. We’re already accustomed to distinguishing letters, even if they’re printed in a smallish font, and they can be packed together closely. It is true that the text-based version of the supermarket program would probably take up less space that a visual version.
This complaint came up a lot in relation to mathematical tasks, which are often built up by composing a large number of simpler operations. This can become a massive pain if the individual operations take up a lot of space:
Graphs take up much more space on the screen than text. Grab a pen and draw a computational graph of a Fourier transformation! It takes up a whole screen. As a formula, it takes up a tiny fraction of it. Our state machine used to take up about 2m x 2m on the wall behind us.
Many node-based tools seem to have some kind of special node for typing in maths in a more conventional linear way, to get around this problem.
(Sidenote: this didn’t come up in any of the discussions, but I am curious as to how fundamental this limitation is. Part of it comes from the sheer familiarity of text. The first letters we learned as a child were printed a lot bigger! So presumably we could learn to distinguish closely packed shapes if we were familiar enough with the conventions. At this point, of course, with a small number of distinctive glyphs, it would share a lot of properties with text-based language. See the section on discrete symbols below.)
Linearity
Humans are centered around linear communication. Spoken language is essentially linear, with good use of a stack of concepts. This story-telling mode maps better on a linear, textual representation than on a graphical representation. When provided with a graph, it is difficult to find the start and end. Humans think in graphs, but communicate linearly.
The linearity of text is a feature that is mostly preserved in programming. We don’t literally read one giant 1D line of symbols, of course. It’s broken into lines and there are special structures for loops. But the general movement is vertically downwards. “1.5 dimensions” is a nice description:
When you write text-based code, you are also restricted to 2 dimensions, but it’s really more like 1.5 because there is a heavy directionality bias that’s like a waterfall, down and across. I cannot copy pictures or diagrams into a text document. I cannot draw arrows between comments to the relevant code; I have to embed the comment within the code because of this dimensionality/directionality constraint. I cannot “touch” a variable (wire) while the program is running to inspect its value.
It’s true that many visual environments give up this linearity and allow more general positioning in 2D space (arbitrary placing of boxes and arrows in node-based programming, for example, or the 2D grids in spreadsheets). This has benefits and costs.
On the costs side, linear structures are a good match to the sequential execution of program instructions. They’re also easy to navigate and search through, top to bottom, without getting lost in branching confusion. Developing tools like autoformatters is more straightforward (we saw this come up in the earlier section on missing tooling).
On the benefits side, 2D structures give you more of an expressive canvas for communicating the meaning of your program: grouping similar items together, for example, or using shapes to distinguish between types of object.
In LabVIEW, not only do I have a 2D surface for drawing my program, I also get another 2D surface to create user interfaces for any function if I need. In text-languages, you only have colors and syntax to distinguish datatypes. In LabVIEW, you also have shape. These are all additional dimensions of information.
They can also help in remembering where things are:
One of the interesting things I found was that the 2-dimensional layout helped a lot in remembering where stuff was: this was especially useful in larger programs.
And the match to sequential execution is less important if your target domain is also non-sequential in some way:
If the program is completely non-sequential, visual tools which reflects the structure of the program are going to be much better than text. For example, if you are designing a electronic circuit, you draw a circuit diagram. Describing a electronic circuit purely in text is not going to be very helpful.
Written text IS a visual medium. It works because there is a finite alphabet of characters that can be combined into millions of words. Any other “visual” language needs a similar structure of primitives to be unambiguously interpreted.
This is a particularly important point that was brought up by several commenters in different threads. Text is built up from a small number of distinguishable characters. Text-based programming languages add even more structure, restricting to a constrained set of keywords that can only be combined in predefined ways. This removes ambiguity in what the program is supposed to do. The computer is much stupider than a human and ultimately needs everything to be completely specified as a sequence of discrete primitive actions.
At the opposite end of the spectrum is, say, an oil painting, which is also a visual medium but much more of an unconstrained, freeform one, where brushstrokes can swirl in any arbitrary pattern. This freedom is useful in artistic fields, where rich ambiguous associative meaning is the whole point, but becomes a nuisance in technical contexts. So different parts of the spectrum are used for different things:
Because each method has its pros and cons. It’s a difference of generality and specificity.
Consider this list as a ranking: 0 and 1 >> alphabet >> Chinese >> picture.
All 4 methods can be useful in some cases. Chinese has tens of thousands of characters, some people consider the language close to pictures, but real pictures have more than that (infinite variants).
Chinese is harder to parse than alphabet, and picture is harder than Chinese. (Imagine a compiler than can understand arbitrary picture!)
Visual programs are still generally closer to the text-based program end of the spectrum than the oil painting one. In a node-based programming language, for example, there might be a finite set of types of boxes, and defined rules on how to connect them up. There may be somewhat more freedom than normal text, with the ability to place boxes anywhere on a 2D canvas, but it’s still a long way from being able to slap any old brushstroke down. One commenter compared this to diagrammatic notation in category theory:
Category theorists deliberately use only a tiny, restricted set of the possibilities of drawing diagrams. If you try to get a visual artist or designer interested in the diagrams in a category theory book, they are almost certain to tell you that nothing “visual” worth mentioning is happening in those figures.
Visual culture is distinguished by its richness on expressive dimensions that text and category theory diagrams just don’t have.
Drag-n-drop editors are a bit further towards the freeform end of the spectrum, allowing UI elements to be resized continuously to arbitrary sizes. But there are still constraints — maybe your widgets have to be rectangles, for example, rather than any old hand-drawn shape. And, as discussed in earlier sections, there’s a tension between visual specificity and dynamic programming of many potential visual states at once. Drag-n-drop editors arguably lose a lot of the features of ‘true’ languages by giving up structure, and more programmatic elements are likely to still use a constrained set of primitives.
Finally, there was an insightful comment questioning how successful these constrained visual languages are compared to text:
I am not aware of a constrained pictorial formalism that is both general and expressive enough to do the job of a programming language (directed graphs may be general enough, but are not expressive enough; when extended to fix this, they lose the generality.)
… There are some hybrids that are pretty useful in their areas of applicability, such as state transition networks, dataflow models and Petri nets (note that these three examples are all annotated directed graphs.)
This could be a whole blog post topic in itself, and I may return to it in a follow-up post — Dutilh Novaes makes similar points in her discussion of tractability vs expressiveness in formal logic. Too much to go into here, but I do think this is important.
Grab bag of other interesting points
This section is exactly what it says — interesting points that didn’t fit into any of the categories above.
Allowing syntax errors
This is a surprising one I wouldn’t have thought of, but it came up several times and makes a lot of sense on reflection. A lot of visual programming tools are too good at preventing syntax errors. Temporary errors can actually be really useful for refactoring:
This is also one of the beauties of text programming. It allows temporary syntax errors while restructuring things.
I’ve used many visual tools where every block you laid out had to be properly connected, so in order to refactor it you had to make dummy blocks as input and output and all other kinds of crap. Adding or removing arguments and return values of functions/blocks is guaranteed to give you rsi from excessive mousing.
I don’t quite understand why this is so common in visual tools specifically, but it may be to do with the underlying representation? One comment pointed out that this was a more general problem with any kind of language based on an abstract syntax tree that has to be correct at every point:
For my money, the reason for this is that a human editing code needs to write something invalid – on your way from Valid Program A to Valid Program B, you will temporarily write Invalid Jumble Of Bytes X. If your editor tries to prevent you writing invalid jumbles of bytes, you will be fighting it constantly.
The only languages with widely-used AST-based editing is the Lisp family (with paredit). They get away with this because:
Lisp ‘syntax’ is so low-level that it doesn’t constrain your (invalid) intermediate states much. (ie you can still write a (let) or (cond) with the wrong number of arguments while you’re thinking).
Paredit modes always have an “escape hatch” for editing text directly (eg you can usually highlight and delete an unbalanced parenthesis). You don’t need it often (see #1) – but when you need it, you really need it.
Maybe this is more common as a way to build a visual language?
Hybrids
Take what we all see at the end of whiteboard sessions. We see diagrams composed of text and icons that represent a broad swath of conceptual meaning. There is no reason why we can’t work in the same way with programming languages and computer.
Another recurring theme was a wish for hybrid tools that combined the good parts of visual and text-based tools. One example that came up in the ‘information density’ section was doing maths in a textual format in an otherwise visual tool, which seems to work quite well:
UE4 Blueprints are visual programming, and are done very well. For a lot of things they work are excellent. Everything has a very fine structure to it, you can drag off pins and get context aware options, etc. You can also have sub-functions that are their own graph, so it is cleanly separated. I really like them, and use them for a lot of things.
The issue is that when you get into complex logic and number crunching, it quickly becomes unwieldy. It is much easier to represent logic or mathematics in a flat textual format, especially if you are working in something like K. A single keystroke contains much more information than having to click around on options, create blocks, and connect the blocks. Even in a well-designed interface.
Tools have specific purposes and strengths. Use the right tool for the right job. Some kind of hybrid approach works in a lot of use cases. Sometimes visual scripting is great as an embedded DSL; and sometimes you just need all of the great benefits of high-bandwidth keyboard text entry.
Even current text-based environments have some hybrid aspect, as most IDEs support syntax highlighting, autocompletion, code folding etc to get some of the advantages of visualisation.
Visualising the wrong thing
The last comment I’ll quote is sort of ranty but makes a deep point. Most current visual tools only visualise the kind of things (control flow, types) that are already displayed on the screen in a text-based language. It’s a different representation of fundamentally the same thing. But the visualisations we actually want may be very different, and more to do with what the program does than what it looks like on the screen.
‘Visual Programming’ failed (and continues to fail) simply because it is a lie; just because you surround my textual code with boxes and draw arrows showing the ‘flow of execution’ does not make it visual! This core misunderstanding is why all these ‘visual’ tools suck and don’t help anyone do anything practical (read: practical = complex systems).
When I write code, for example a layout algorithm for a set of gui elements, I visually see the data in my head (the gui elements), then I run the algorithm and see the elements ‘move’ into position dependent upon their dock/anchor/margin properties (also taking into account previously docked elements positions, parent element resize delta, etc). This is the visual I need to see on screen! I need to see my real data being manipulated by my algorithms and moving from A to B. I expect with this kind of animation I could easily see when things go wrong naturally, seeing as visual processing happens with no conscious effort.
Instead visual programming thinks I want to see the textual properties of my objects in memory in fancy coloured boxes, which is not the case at all.
I’m not going to try and comment seriously on this, as there’s almost too much to say — it points toward to a large number of potential tools and visual paradigms, many of which are speculative or experimental. But it’s useful to end here, as a reminder that the scope of visual programming is not just some boxes with arrows with between.
Final thoughts
This post is long enough already, so I’ll keep this short. I collected all these quotes as a sort of exploratory project with no very clear aim in mind, and I’m not yet sure what I’m going to do with it. I probably want to write at least one follow-up post making links back to the Dutilh Novaes and Ong books on text as a technology. Other than that, here are a few early ideas that came to mind as I wrote it:
How much is ‘visual programming’ a natural category? I quickly discovered that commmenters had very different ideas of what ‘visual programming’ meant. Some of these are at least partially in tension with each other. For example, drag-n-drop UI editors often allow near-arbitrary placement of UI elements on the screen, using an intuitive visual interface, but are not necessarily very programmatic. On the other hand, node-based editors allow complicated dynamic logic, but are less ‘visual’, reproducing a lot of the conventions of standard text-based programming. Is there a finer-grained classification that would be more useful than the generic ‘visual programming’ label?
Meaning vs fluency. One of the most appealing features of visual tools is that they can make certain inherently visual actions much more intuitive (a colour picker is a very simple example of this). And proponents of visual programming are often motivated by making programming more understandable. At the same time, a language needs to be a fluent medium for writing code quickly. At the fluent stage, it’s common to ignore the semantic meaning of what you’re doing, and rely on unthinkingly executing known patterns of symbol manipulation instead. Desigining for transparent meaning vs designing for fluency are not the same thing — Vim is a great example of a tool that is incomprehensible to beginners but excellent for fluent text manipulation. It could be interesting to explore the tension between them.
‘Missing tooling’ deep dives. I’m not personally all that interested in following this up, it takes me some way from the ‘text as technology’ angle I came in from, but it seems like an obvious one to mention. The ‘missing tooling’ subsections of this post could all be dug into in far more depth. For each one, it would be valuable to compare many existing visual environments, and understand what’s already available and what the limitations are compared to normal text.
Is ‘folk wisdom from internet forums’ worth exploring as a genre of blog post? Finally, here’s a sort of meta question, about the form of the post rather than the content. There’s an extraordinary amount of hard-to-access knowledge locked up in forums like Hacker News. While writing this post I got distracted by a different rabbit hole about Delphi, which somehow led me to another one about Smalltalk, which… well, you know how it goes. I realised that there were many other posts in this genre that could be worth writing. Maybe there should be more of them?
If you have thoughts on these questions, or on anything else in the post, please leave them in the comments!
(This is a speedrun post, where I set a one hour timer to see what I can find out about a subject. See the category tag for more examples.)
I’m currently reading Catarina Dutilh Novaes’s Formal Languages in Logic, and one part of the section on the historical development of mathematical notation jumped out at me as potentially interesting. Abbaco (‘abacus’) schools were a kind of practical school in medieval southern Europe that trained the sons of merchants and artisans in useful mathematics for bookkeeping and business. Apparently the mathematical culture associated with these schools actually went beyond the university education of the time in some respects, and helped push forward the development of algebra:
Indeed, modern algebra (and its notation) will ultimately emerge from the sub-scientific tradition of the abbaco schools, rather than the somewhat solidified academic tradition taught at the medieval universities.
I find these sort of semi-informal institutions on the edges of academia intriguing… I’m not sure how much I care about the details, but it seems worth an hour of investigation at least. There’s also a mention of Leonardo da Vinci and Danti Alighieri attending these schools, which could be interesting to follow up.
This speedrun session is also a bit different because we’re trying out a group speedrun event, and David MacIver and Eve Bigaj have also joined. Let’s see how it goes… As usual I typed this as I went and have done only minor tidying up afterwards, so there may be a bunch of typos and dodgy formatting.
There’s a wikipedia article, but it isn’t very long. Looks like there are a few other useful links though
Abacus school is a term applied to any Italian school or tutorial after the 13th century, whose commerce-directed curriculum placed special emphasis on mathematics, such as algebra, among other subjects. These schools sprang after the publication of Fibonacci’s Book of the Abacus and his introduction of the Hindu-Arabic numeral system. In Fibonacci’s viewpoint, this system, originating in India around 400 BCE, and later adopted by the Arabs, was simpler and more practical than using the existing Roman numeric tradition. Italian merchants and traders quickly adopted the structure as a means of producing accountants, clerks, and so on, and subsequently abacus schools for students were established.
So, yep, practical education for merchants and traders.
Significant for a couple of reasons. First they got rid of Roman numerals.
The number of Roman characters a merchant needed to memorize to carry out financial transactions as opposed to Hindu-numerals made the switch practical. Commercialists were first introduced to this new system through Leonardo Fibonacci, who came from a business family and had studied Arabic math. Being convinced of its uses, abacus schools were therefore created and dominated by wealthy merchants, with some exceptions
Also they were instrumental in rising literacy levels.
Nothing about algebra here! Another thing on the search page mentioned Cardano though so hopefully there will be a link.
Then there’s a bunch of stuff about the school system.
Italian abacus school systems differed more in their establishment than in their curriculum during the Middle Ages. For example, institutions and appointed educators were set up in a number of ways, either through commune patronage or independent masters’ personal funds. Some abbaco teachers tutored privately in homes. All instructors, however, were contractually bound to their agreement which usually meant that they could supplement their salary with tuition fees or other rates.
Could be an overlap here with medieval guild funding of universities (e.g. in Bologna), another subject I’m considering speedrunning on.
Independent teachers could also be hired by the commune, but for lower wages.[19] Most times, free-lance masters were contracted by a group of parents in a similar fashion to that of communal agreements, thus establishing their own school if the number of students being tutored was significant in size.[20] Abbaco apprentices training to become masters could also tutor household children and pay for their studies simultaneously.
Last (short) section is on the curriculum.
Arithmetic, geometry, bookkeeping, reading and writing in the vernacular were the basic elementary and secondary subjects in the abbaco syllabus for most institutions, which began in the fall, Mondays through Saturdays.
… Mathematical problems dealt with the everyday exchange of different types of goods or monies of differing values, whether it was in demand or in good quality, and how much of it was being traded. Other problems dealt with distribution of profits, where each member invested a certain sum and may have later withdrawn a portion of that amount
Well that wasn’t a very informative article. There isn’t one in Italian either, just Arabic (same info as English) and Persiian (a stub where I’m not going to even bother to hit translate). So I need to leave wikipedia very early.
OK, this looks good and more what I was after. ‘Solving the Cubic with Cardano – Aspects of Abbaco Mathematics’ by William Branson.
To understand the abbaco mathematics used by Cardano, we have to step back and look at the medieval tradition of abbaco schools and their masters. Though the subject is a fascinating and deep one, there is one particular aspect of this tradition that is crucial in the following account: abbaco masters thought in terms of canonical problems, and one particular canonical problem, the “Problem of Ten,” arises in the solution of the cubic that we will examine.
Quick summary of what they were, similar to wikipedia.
Abbaco mathematics was rhetorical—in Cardano’s time, most of the algebraic symbols with which we are so familiar were either recently invented, concurrent with the Ars Magna, or were well in the future. For example, ‘(+)’ and ‘(–)’ were first recorded in the 1480s, and were not in common use in 1545, when the Ars Magna was published. Robert Recorde would not invent the equals sign until 1557, and the use of letters and exponential notation would have to await Francois Viete in the 1590s and the Geometrie of Rene Descartes of 1637 [Note 2]. What Descartes would write as (x^3=ax+b,) Cardano wrote as “cubus aequalis rebus & numero” [Cardano 1662, Chapter 12, p. 251].
OK this is similar to what Dutilh Novaes was saying, people were solving problems that were algebraic in nature with unknowns to solve for, but the notation was still very wordy.
Rhetorical formulas can be difficult to remember, so algebraic rules were presented with canonical examples, which encoded the rules as algorithms within the examples. Thus, the mind of the abbaco master was a storehouse of such canonical examples, to which he compared the new problems that he came across in his work. When he recognized a parallel structure between the new problem and a canonical problem, he could solve the new problem by making appropriate substitutions into the canonical example.
So these ‘wordy’ forms still had some kind of canonical structures, it wasn’t just free text but was a kind of notation.
Such canonical examples occurred even in the foundational texts of abbaco mathematics, including the Algebra of al-Khwarizmi. An important example for us, one that occurs implicitly in Cardano’s solution to the cubic, is the “problem of ten” [Note 3]. Most abbaco texts had such problems, and one from Robert of Chester’s 1215 translation of al-Khwarizmi’s Algebra into Latin [al-Khwarizmi, p. 111] ran as follows:
Denarium numerum sic in duo diuido, vt vna parte cum altera multiplicata, productum multiplicationis in 21 terminetur. Iam ergo vnam partem, rem proponimus quam cum 10 sine re, quae alteram partem habent, multiplicamus…
In his translation of this passage into English, Louis Karpinski used (x) for ‘rem’ (thing), and so I offer my own translation, without symbols [Note 4]:
Ten numbers in two parts I divide in such a way, in order that one part with the other multiplied has the product of the multiplication conclude with 21. Now therefore one part we declare the thing, and then, with 10 without the thing, which the other part is, we multiply…
My god I can’t even be bothered to read all of that that… very glad we don’t do maths like that now…
The structure of the “problem of ten” was that of a number (a) broken into two parts (x) and (y,) with a condition on the parts; symbolically: [x+y=a\,\,{\rm and}\,\,f(x,y)=b] for some function (f(x,y)) and number (b.) The usual method of solution was to express the two parts as “thing” and “number minus thing” and then to substitute into the condition, as al-Khwarizmi did above. The “problem of ten” was canonical for quadratic problems, and served as a way to remember the rules for solving such problems.
This was used in Cardano’s solution to the cubic, apparently, but there’s no more detail on this page, it just ends there. Looks like a book extract or something.
There’s another MAA page on abbaco schools, though, so I’ll read that next. This is ‘Background: The Abbaco Tradition’ by Randy K. Schwarz.
Bit more detail on where these schools were:
They arose first in northern Italy, whose economy was the most vibrant in Europe during this period (Spiesser 2003, pp. 34-35). A banker and official in Florence, Italy, reported that in 1345 at least 1,000 boys in that city alone were receiving instruction in abbaco and algorismo (Biggs 2009, p. 73). Such schools also began to appear in neighboring southern France, and a few in Catalonia (the area around Barcelona, Spain) and coastal North Africa. These four regions of the western Mediterranean had extensive trade and cultural ties with one another at the time, so it isn’t surprising that they shared methods of practical mathematics and its instruction (Høyrup 2006).
Mentions the Fibonacci book again as a common ancestor. Ah so this is why Fibonacci knew this stuff:
He was only a boy, he reports, when his father, a customs official representing Pisan merchants at their trading enclave of Bugia, in what is now Algeria, brought him to the customs house there to be taught Hindu-Arabic numerals and arithmetic (Sigler 2002, pp. 3, 15)
This article is part of a series on something called the Pamiers manuscript, which translated some of this into French maybe? or some language in modern France anyway. look up later if time.
Nice picture of teaching in an abbaco school here.
In general, the abbaco texts offered practical, simplified treatments in which mathematical techniques were distilled into easy-to-remember rules and algorithms. The focus was on how to carry these out rather than on justifying the theory behind them. At the same time, the books were often innovative in their solutions to particular problems and especially in their pedagogical approach: their presentation was popular, and they introduced the use of illustrations and vernacular languages to the history of mathematics textbooks.
Reference here to something called Swetz 1987, ‘Capitalism and Arithmetic: The New Math of the 15th Century’.
OK this article finishes here too… and I still have 34 minutes, this might be a difficult speedrun for finding information. I may as well skim the intro page and find out what the Pamiers manuscript is while I’m here.
Pamiers is in the far south of France, south of Toulouse near the Pyrenees. Written in the Languedocian language.
One of the striking features of the Pamiers manuscript is the fact that it includes the world’s earliest known instance in which a negative number was accepted as the answer to a problem for purely mathematical reasons. The fact that this occurred in the context of a commercial arithmetic, rather than a more scholastic or theoretical work, is a surprise.
Ah, nice, this is the sort of thing I was hoping for, new ideas coming up in the context of practical problems.
Back to wikipedia for now, what else can I find?
I found a pdf by Albrecht Heeffer which is very short but does mention one interesting book.
The abbaco or abbacus tradition (spelled with double b to distinguish it from the material calculating device called ‘abacus’) has the typical characteristics of a so-called ‘sub-scientific’ tradition of mathematical practice (coined by Jens Høyrup). It is supported by lay culture, e.g. merchants, artisans and surveyors. Knowledge is disseminated through master-apprentice relationships, often within family relations. Texts, as far as they are extant, are written in the vernacular. The tradition is open to foreign influences, including cross-cultural practices. Typically, the tradition is underrepresented in the history of mathematics.
Dutilh Novaes also mentioned the Høyrup book so maybe that is what I should really be reading. It’s this ‘sub-scientific’ angle that I’m interested in.
Abbaco masters made subtle but important contributions to the development of early symbolism. Their two centuries of algebraic practice paved the road for the development of symbolic algebra during the sixteenth century. They introduced mathematical techniques such as complete induction which is believed to have emerged a century later
Yeah, ok, so this is an interesting subject but I probably need to be reading books to find the good bits, rather than skimming the internet. Similar to Vygotsky speedrun maybe.
Let’s find out what this Høyrup book is called. Ah it must be this book mentioned on his wikipedia page: ‘Jacopo da Firenze’s Tractatus algorismi and early italian abacus culture.’ Yes I’m definitely going to buy these chapters off Springer for 25.95 euros each, sounds like a great idea.
Ah here’s a copy of a pdf by Høyrup! It’s 34 pages so I don’t have time to go into the details, but I can skim it. Hm also it looks like it’s mainly arguing about the centrality of Fibonacci in the tradition, I’m not interested in that, I’m interested in the sub-scientific thing.
First though I’d like to chase up that thing about Dante and da Vinci.
20 minutes left.
Search ‘da Vinci abbacco school’, oh god the results are full of random schools named after him and references to The Da Vinci Code. Must include: abbaco.
I have found another vaguely useful paper though, ‘The Market for Luca Pacioli’s Summa Arithmatica’ by Alan Sangster and others. Something here about the two-track nature of education in Renaissance Italy, with these schools at the practical end.
The curriculum of the vernacular schools emerged from the merchant culture and was designed to prepare sons of merchants and craftsmen for their future working lives [Grendler, 1990]. There was another parallel set of schools, the Latin (either scholastic or humanist) schools, where the sons of the privileged were taught in Latin.
The two sets of schools taught very different subjects. The Latin schools sought to teach the future leaders of society and those that aided them, e.g., secretaries and lawyers [Grendler,1989, p. 311]. They specialized in the trivium of grammar, rhetoric, and logic… On the rare occasions when mathematics was taught in these schools, it took the form of “classical or medieval Latin mathematics” [Grendler, 1989, p. 309]. In contrast to the vernacular schools, boys leaving the humanist schools often went to university.
Hang on, why don’t I just look on da Vinci’s wikipedia page? It just says the following:
Despite his family history, Leonardo only received a basic and informal education in (vernacular) writing, reading and math, possibly because his artistic talents were recognized early.
which would at least be consistent with going to one of these schools. And Dante Alighieri:
Not much is known about Dante’s education; he presumably studied at home or in a chapter school attached to a church or monastery in Florence.
Hm, so what did Dutilh Novaes say? Ah, it’s a quote from Heeffer 2007, ‘Humanist Repudiation of Eastern Influences in Early Modern Mathematics’. Pdf is here. Should have looked this up to start with!
Actually I’m confused because, although this is very relevant looking, it doesn’t have the quote in it at all. Ah well, I may as well read it for the rest of the time anyway (only 5 minutes left!). The thing about Dante and da Vinci isn’t really important.
Here’s some more on the sub-scientific idea:
Jens Høyrup coined the term sub-scientific mathematics for a long tradition of practice which has been neglected by historians. As a scholar working on a wide period of mathematical practice, from Babylonian algebra to the seventeenth century, Høyrup has always paid much attention to the more informal transmission of mathematical knowledge which he calls sub-scientific structures.
This is pretty complicated to skim quickly.
The sub-scientific tradition was a cross-cultural amalgam of several traditions. Merchant type arithmetic and recreational problems show a strong similarity with Indian sources. Algebra descended from the Arabs. By the time Regiomontanus learned algebra in Italy it was practiced by abbaco masters for more than 250 years. The tradition of surveying and mensuration within practical geometry goes back to Babylonian times.
Some stuff on ‘proto-algebraic rules’.
Our main hypothesis is that many recipes or precepts for arithmetical problem solving, in abbaco texts and arithmetic books before the second half of the sixteenth century, are based on proto-algebraic rules. We call these rules proto-algebraic because they are, or could be based originally on algebraic derivations. Yet their explanation, communication and application do not involve algebra at all. Proto-algebraic rules are disseminated together with the problems to which they can be applied. The problem functions as a vehicle for the transmission of this sub-scientific structure. Little attention has yet been given to sub-scientific mathematics or proto-algebraic rules.
Ding! Time’s up.
Hm, that was kind of annoying to do a speedrun on, because the Wikipedia article was so short and I had to jump quickly to a bunch of other sources which all either had very limited detail or way too much detail. I never did get to the bottom of the Dante and da Vinci thing.
I’m also still not that clear on the details of exactly what new techniques they introduced, but looks like they were relevant to Cardano’s solution of the cubic, and also to the use of negative numbers in problems. They also introduced a bunch of schematic templates for solving problems, which later developed into modern algebraic notation.
The idea of ‘sub-scientific’ traditions sounds interesting more generally too, maybe I should look up the Høyrup book. Overall this looks like a topic where I’m better off reading books and papers than skimming random web pages.

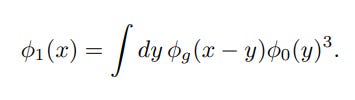
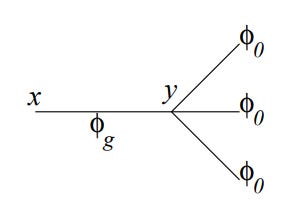
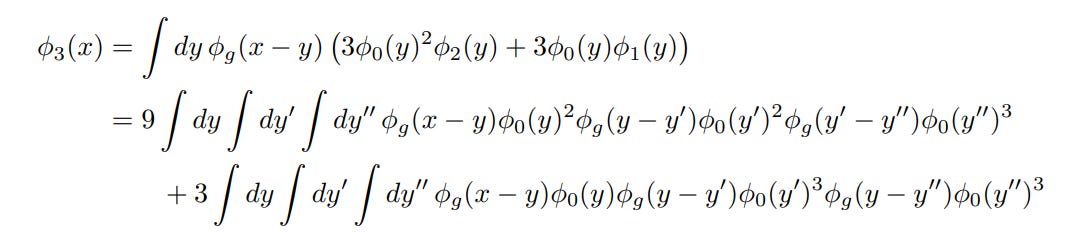
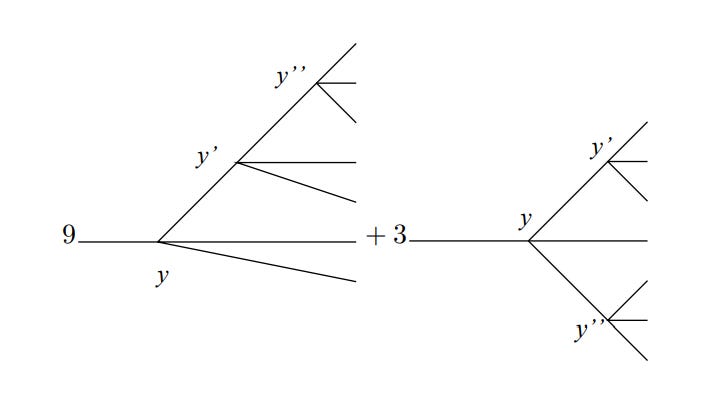



#/media/File:Scratch_2.0_Default_screen.png){kind=link}
{kind=link}
{kind=link}