Right, so on the plus side I haven’t completely lost my remaining threads of sanity by thinking about negative probability too much. Unfortunately that’s mainly because I’ve found it really hard to concentrate this month. THERE ARE TOO MANY INTERESTING THINGS IN THE WORLD, and I keep getting distracted. I’ll talk briefly about a couple of these in the last section of this newsletter, but most of this one is an incoherent braindump about negative probability, sorry.
Negative probability
I started off by rereading this paper by Edward Allen on ‘signed probability theory’, which I talked about briefly way back in February. It’s pretty obscure and not mentioned in most reviews of negative probability, I think possibly because it uses this slightly different name. I didn’t find it until I eventually thought to search for ‘signed probability’ or something.
Allen’s paper is unusual because it does at least attempt to give a concrete example with some kind of interpretation of the mathematics. This example is pretty contrived, and generally just not something people ever actually do in this situation, but it deserves some kind of points for trying. My hope is that I can map this formalism onto something more convincing.
Allen’s interpretation is something like the Donald Rumsfeld school of probability. You use normal probabilities to represent your ‘known unknowns’, which are positive and add up to 1. But there might also be some ‘unknown unknowns’, things that don’t fit into your current model of the situation. These are modelled as ‘latent probabilities’ that are negative and sum to -1. Eventually reality comes and hits you over the head with these unknown unknowns, so that they become known unknowns. At this point you update your probabilities, and the latent negative probabilities become actual positive ones.
This will hopefully become slightly clearer if I reproduce his example. A postal clerk is sorting addresses by zip code:
In the course of his work he begins to notice that a considerable volume of the mail addressed to 84321 (my own home town) is intended not just for Logan, Utah but for Utah State University as well. So he makes the suggestion that a new zip code be created just for the University. (This was in fact done.) The result is that a considerable volume of mail that was handled and sorted by the post office at least twice is now handled and sorted one less time.
This new zip code is an ‘unknown unknown’ that the clerk couldn’t have predicted within the current system.
Allen assumes for concreteness that there were 20 sorting categories before the zip code change, and 21 after. He assigns equal probability of 0.05 to each of the 20 ‘known unknown’ categories before the change, and then creates the 21st category by splitting the probability for the 20th cell into two with probability 0.025 each. So we have this:
| Address | Before | After |
| x1 – x19 | 0.05 | 0.05 |
| x20 | 0.05 | 0.025 |
| x21 | 0 | 0.025 |
| Residuum | 0 | 0 |
The ‘residuum’ category is Allen’s catch-all category for whatever stuff is left over. In this case the other probabilities add up to 1 so this is zero.
Now for the bit with negative probabilities. Allen imagines those 0.025 probabilities for x20 and x21 sitting there ‘latent’ beforehand. These probabilities are negative. Also, the total set of negative probabilities should add up to -1, so the rest goes into the ‘residuum’. After the change the probabilities for x20 and x21 are ‘actualised’ and become positive. So the table for latent probabilities (the negative ones) reads:
| Address | Before | After |
| x1 – x19 | 0 | 0 |
| x20 | -0.025 | 0 |
| x21 | -0.025 | 0 |
| Residuum | -0.95 | -1 |
Putting this all into one table for convenience, and also including the ‘signed’ probability (actual plus latent), we get:
| Before | After | |||||
| Address | Actual | Latent | Signed | Actual | Latent | Signed |
| x1 – x19 | 0.05 | 0 | 0.05 | 0.05 | 0 | 0.05 |
| x20 | 0.05 | -0.025 | 0.025 | 0.025 | 0 | 0.025 |
| x21 | 0 | -0.025 | -0.025 | 0.025 | 0 | 0.025 |
| Residuum | 0 | -0.95 | -0.95 | 0 | -1 | -1 |
So what? Does this formalism actually help you think about the problem at all? The main thing Allen gets out of it is that he also computes the Shannon information, and this is quite nice because the signed information is conserved, whereas the actual and latent information aren’t. Outside of that, I’m not convinced.
I think I can see a use case that is somewhat parallel, though, and might be worth considering specifically for quantum theory. We normally assume that the current state of a system is only dependent on its past state, and not its future state. So, for example, if we toss a coin, we expect the outcome to be determined by its trajectory before it landed. We don’t expect it to also be influenced by what happens after it lands. Which is pretty reasonable for a macroscopic coin!
I’ve talked briefly in a previous newsletter about Huw Price’s Time’s Arrow and Archimedes’ Point, which is a book that makes the case for assuming time symmetry at the micro level, so that both the past and future are relevant for determining the current state. I’m well aware that this sounds pretty weird if you haven’t considered it before, but I’m not going to spend much time trying to justify this today – I’m just assuming that this is a good idea and running with it.
I will give one bit of background, though. A good way of thinking about this is to consider spatial problems – a statics problem like a hanging chain, for instance. We do expect the shape of the hanging chain to depend on the height of the chain at both ends – we don’t expect just the left hand boundary condition or just the right hand one to be relevant. Compare this with dynamics problems, where we normally consider only the initial conditions, and then integrate forwards in time. Price’s thesis is something like: ‘at the micro level, we need to think about dynamics problems in a similar way to statics problems: we need to consider the final state as well as the initial one.’
Now for the connection to negative probability. My (unjustified and vaguely worded!) claim is:
Negative probabilities come up when you’ve already ‘used up’ your probability space on past conditions, and set the total to 1, but there is actually a dependence on future conditions that you don’t know about.
For example, imagine a simplified coin with, I dunno, only four equally possible microstates representing possible ways of throwing, two of which lead to the macrostate ‘heads’ and two to ‘tails’. So you expect probability ½ for heads, ½ for tails, and the total sums to 1. This is fine in the normal case where only the past matters. I want to claim that negative probabilities will crop up if that current state also depends on the future microstate, but you aren’t aware of that, so you’ve already made everything you do know about sum to 1.
This sort of fits with Allen’s postal clerk example. In his example the ‘unknown unknowns’ are some stuff he learns about later, when he’s already filled up his probability space. I would like the ‘unknown unknowns’ to instead be boundary conditions in the future. This is fairly aesthetically pleasing – the sign of the probability would hopefully pick out the direction of causation. Also, it seems plausible to have the past and future as equally relevant, in which case it makes sense to have the future conditions add up to -1 if the past ones already add up to 1. I’ve seen vaguely similar attempts at interpretation, where a negative probability indicates the probability of an event being undone, but never anything that’s fleshed out really convincingly. It seems worth a try, and understanding better whether this can be made to work was one of my underlying motivations for picking out that van Enk paper to concentrate on this year.
I’m hoping it might be easier to think about all this by constructing a spatial analogue. My example is an ant who is constrained to travel from left to right, and who also considers left-to-right motion to be the Unquestionable Order Of Things, such that it would never even consider the option of a right-to-left cause. I then want to give it some system to consider that depends on conditions to both the left and the right, and see what happens.
I spent a lot of time this month playing with variants of the following model, which is due to Ken Wharton, just to get a feel for it:
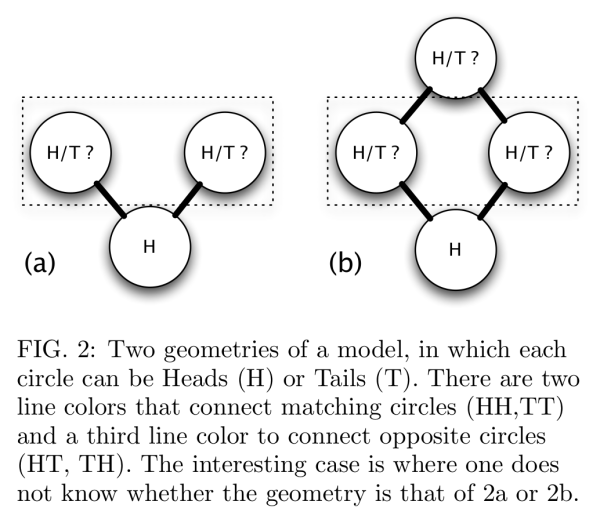
The idea of this is that there are some underlying microstates (the colours of the connecting rods) that determine the states of the circles, and the rules for these (blue and green connect matching circles, red connect opposites) are symmetric. However, the ant will only consider rules where circles on the left affect circles on the right. This might be workable for geometry a), but the loop in geometry b) imposes a constraint that rules out some microstates.
(For example, imagine that the bottom two rods are blue in b), so that the middle two coins are also H. Then take the top left rod as blue and the top right as red. That’s no good: the blue rod wants the top circle to be H and the red rod wants it to be T. So this particular microstate is ruled out.)
I could continue with this model and try and make the link to negative probabilities, but I think I want to try something slightly different first, and do a direct discretisation of a boundary value problem. Something like x’’ + x = 0, with boundary conditions at each end. Ideally with only three points, and ideally with each point only being able to take the values 0 and 1. That might be too trivial, but I have a vague hope that something like this can be mapped onto the Spekkens toy model or van Enk’s extension of it. I now understand that the four boxes of that model make up a discrete phase space; what I’m now looking for is a dynamics problem that can be drawn as a trajectory on that phase space.
I don’t know, it’s all too unclear at this point, and I doubt much of that made much sense. But actually I’m a lot clearer than I was this time last month, so that’s progress of a sort.
Other stuff this month
- I wrote up a review of The Reflective Practitioner for the blog. It’s basically the same as the one in the newsletter, but a bit more polished. I’d like to start doing that a bit more often. The ‘have to get something out at the end of the month’ format is great for producing a lot of text without fussing about quality too much, but it would be good to go back to some of it and clean it up, or work fragments into a full post.
- I had an interesting email conversation early in the month with David Chapman, which started from this paper, which uses the reclassification of Pluto as an example of drawing boundaries between concepts. I spent quite a while at the beginning of the year thinking about this example, because it seems to be a popular choice! There was an SSC post which said something like ‘Chapman and Yudkowsky are talking about exactly the same thing in different language’, and it was fairly clear to me that that was not the case, and I spent some time picking apart how they use the same example in very different ways. I got very bogged down in confusing technicalities and still have an unfinished draft on this. After the email chain we’re still pretty bogged down in technicalities, but got a bit further!
- I’ve been thinking about the Cognitive Reflection Test, and the relation to the decoupling idea I was talking about a few months ago. I wrote a low-effort tumblr post on the CRT ages ago, which I copied over to my proper blog, and it’s picked up some amazingly good comments given the quality of the original. This month I’ve had a long conversation thread on there with commenter ‘anders’, trying to understand how we think about about various maths problems, which is well worth reading. I’ll try to distill some of that into a proper post some time.
Next month
I’m going to keep plugging on with negative probabilities. Lots more still to do. Work is probably going to get busier, so I might not have so much spare energy for thinking about things, but given the TOO MANY INTERESTING THINGS IN THE WORLD there’s a pretty high chance of me getting distracted anyway.
Thanks for reading, and I will try to make next month’s one less of a mess.
Cheers,
Lucy
