OK, so this is where I go back through everything from the last post, but this time show how all the fiddling around with boxes relates back to quantum physics, and also go into some technical details like explaining what I meant by ‘half the information’ in the discussion at the end. This is unavoidably going to need more maths than the last post, and enough quantum physics knowledge to be OK with qubits and density matrices. I’ll start by translating everything into a standard physics problem.
Qubit phase space
So, first off, instead of the ‘strange machine’ of the last post we will have a qubit state – as a first example I’ll take the 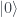

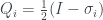

For


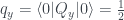
This can be represented on the same sort of 2×2 grid I used in the previous post:
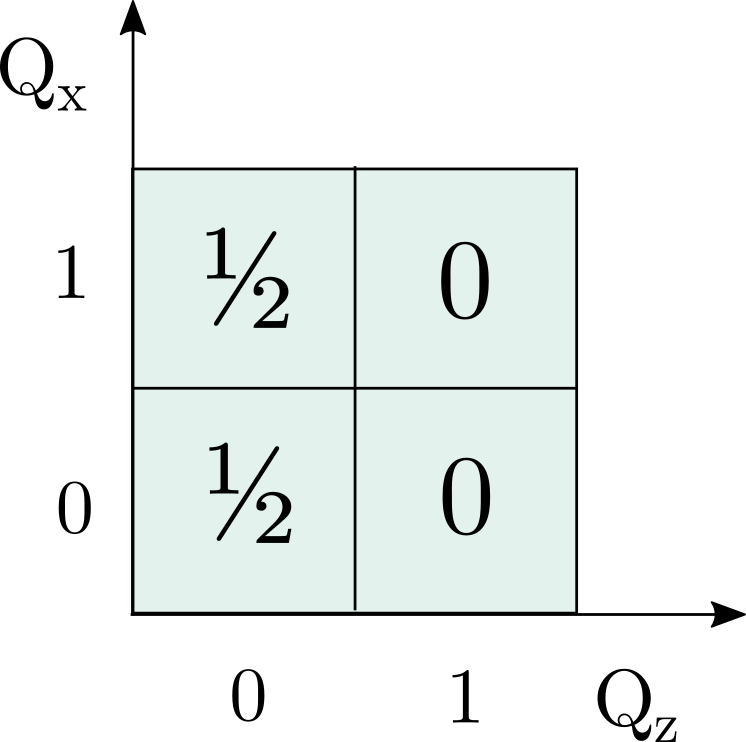
The 




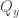
The 2×2 grid is called the phase space of the qubit, and the function that assigns probabilities to each cell is called the Wigner function 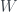
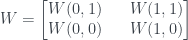
For much more detail on how this all works, the best option is probably to read Wootters, who developed a lot of the ideas in the first place. There’s his original paper, which has all the technical details, and a nice follow-up paper on Picturing Qubits in Phase Space which gives a bit more intuition for what’s going on.
In the previous post I gave the following formula for the Wigner function:
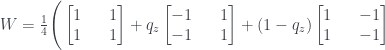
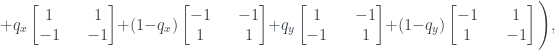
which simplifies to
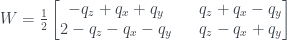
This is a somewhat different form to the standard formula for the Wigner function, but I’ve checked that they’re equivalent. I’ve put the details on a separate notes page here, in a sort of blog post version of the really boring technical appendix you get at the back of papers.
Magic states
As with the example in the last blog post, it’s possible to get qubit states where some of the values of the Wigner function are negative. The numbers don’t work out so nicely this time, but as one example we can take the qubit state 
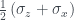
The Wigner function for 

with one negative entry. I learned while writing this that the states with negative values are called magic states by quantum computing people! These are the states that provide the ‘magic’ for quantum computing, in terms of giving a speed-up over classical computing. I’d like be able to say more about this link, but I’ll never finish the post if I have to get my head around all of that too, so instead I’ll link to this post by Earl Campbell that goes into more detail and points to some references. A quick note on the geometry, though:
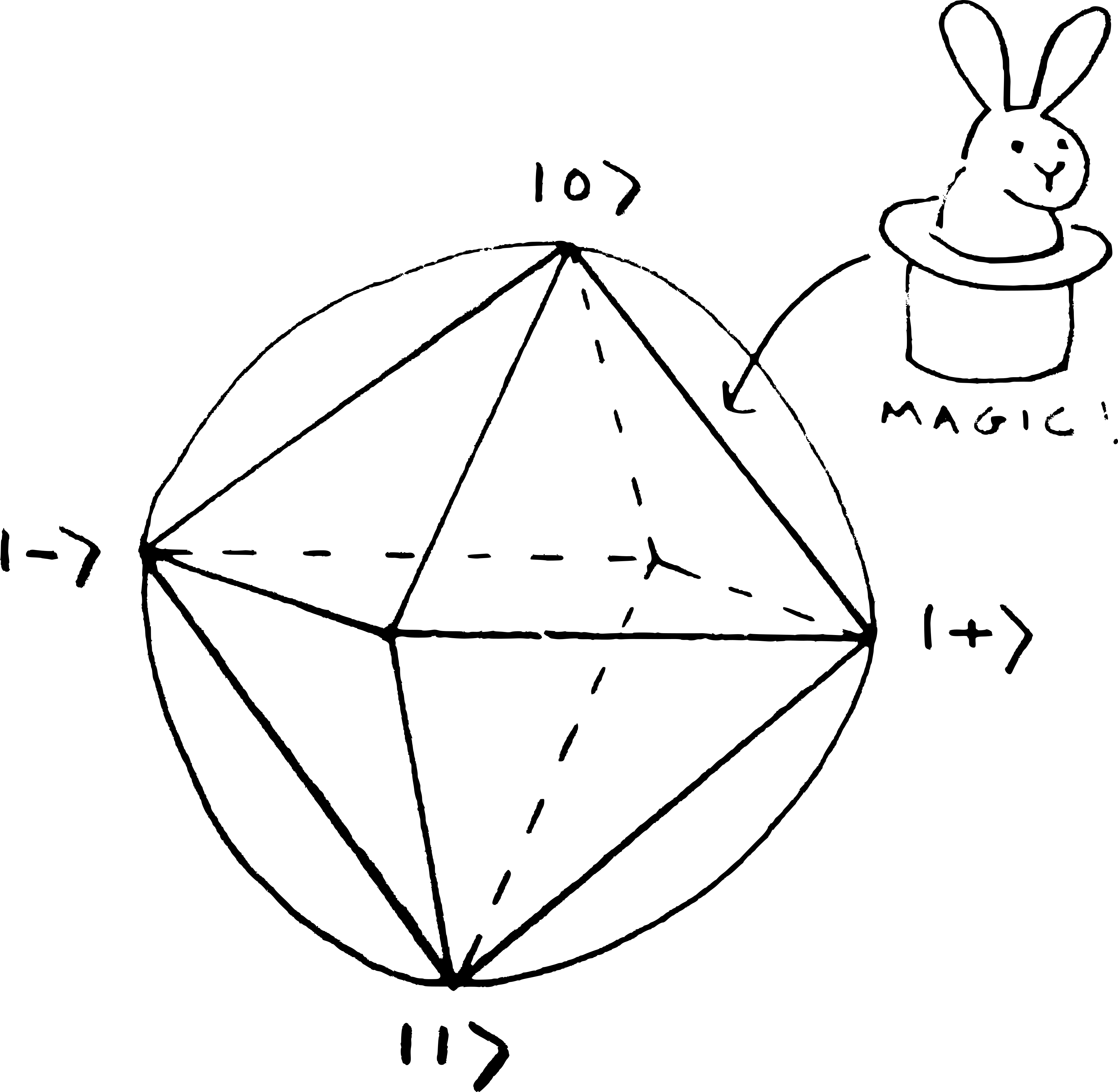
The six eigenvectors of the Pauli matrices form the corners of an octahedron on the Bloch sphere, as in my dubious sketch above. We’ve already seen that the 
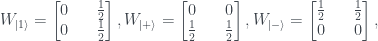
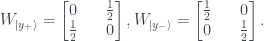
The other states on the surface of the octahedron or inside it also have no magic. The magic states are the ones outside the octahedron, and the further they are from the octahedron the more magic they are. So the most magic states are on the surface of the sphere opposite the middle of the triangular faces.
Half the information
Why can’t we have a probability of 
The second constraint is more interesting. Taking the
This turns out to be the most information you can get from any qubit state, in some sense. I say ‘in some sense’ because it’s a pretty odd definition of information.
I learned about this from a fascinating paper by van Enk, A toy model for quantum mechanics, which was actually my starting point for thinking about this whole topic. He starts with the Spekkens toy model, a very influential idea that reproduces a number of the features of quantum mechanics using a very simple model. Again, this is too big a topic to get into all the details, but the most basic system in this model maps to the six ‘non-magic’ qubit states listed above, in the corners of the octahedron. These all share the half-the-knowledge property of the
Now van Enk’s aim is to extend this idea of ‘half the knowledge’ to more general probability distributions over the four boxes. But this requires having some kind of measure 

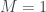

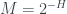
where 

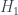
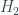
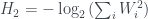
where the 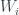



Why this particular entropy measure? That’s something I don’t really understand. Van Enk describes it as ‘the measure of information advocated by Brukner and Zeilinger’, and links to their paper, but so far I haven’t managed to follow the argument there, either. If anyone reads this and has any insight, I’d like to know!
Questions
In some ways, I know a lot more about negative probabilities than I did when I started getting interested in this. But conceptually I’m almost as confused as I was at the start! I think the main improvement is that I have some more focussed questions to be confused about:
- Is the way of decomposing the Wigner function that I described in these posts any use for making sense of the negative probabilities? I found it quite helpful for Piponi’s example, in giving some more insight into how the negative value connects to that particular answer being ‘especially inconsistent’. Is it also useful for thinking about qubits?
- Any link to the idea of negative probabilities representing events ‘unhappening’? As I said at the beginning of the first post, I love this idea but have never seen it fully developed anywhere in a satisfying way.
- What’s going on with this collision entropy measure anyway?
I’m not a quantum foundations researcher – I’m just an interested outsider trying to understand how all these ideas fit together. So I’m likely to be missing a lot of context that people in the field would have. If you read this and have pointers to things that I’m missing, please let me know in the comments!

Not related to this specific blog post, but given your interest in intuition/math you might enjoy “Proofs and refutations” by Lakatos.
LikeLike
I bought a copy of that recently, haven’t got round to it yet! I’ve read an excerpt before – an early part of the dialogue about Euler’s theorem for polyhedra – and that was good, so I should really read the rest.
LikeLike
about theeasure of information that you mention, please see my two paper
https://doi.org/10.48550/arXiv.2201.04407
https://doi.org/10.48550/arXiv.quant-ph/0203102
LikeLike