I’ve been thinking about the idea of negative probabilities a lot recently, and whether it’s possible to make any sense of them. (For some very muddled and meandering background on how I got interested in this, you could wade through my ramblings here, here, here and here, but thankfully none of that is required to understand this post.)
To save impatient readers the hassle of reading this whole thing: I’m not going to come up with any brilliant way of interpreting negative probabilities in this blog post! But recently I did notice a few things that are interesting and that I haven’t seen collected together anywhere else, so I thought it would be worth writing them up.
Now, why would you even bother trying to make sense of negative probabilities? I’m not going to go into this in any depth – John Baez has an great introductory post on negative probability that motivates the idea, and links to a good chunk of the (not very large) literature. This is well worth reading if you want to know more. But there are a couple of main routes that lead people to get interested in this thing.
The first route is pretty much pure curiosity: what happens if we try extending the normal idea of probabilities to negative numbers? This is often introduced in analogy with the way we often use negative numbers in applications to simplify calculations. For example, there’s a fascinating discussion of negative probability by Feynman which starts with the following simple situation:
A man starting a day with five apples who gives away ten and is given eight during the day has three left. I can calculate this in two steps: 5 – 10 = -5 and -5 + 8 = 3.
The final answer is satisfactorily positive and correct although in the intermediate steps of calculation negative numbers appear. In the real situation there must be special limitations of the time in which the various apples are received and given since he never really has a negative number, yet the use of negative numbers as an abstract calculation permits us freedom to do our mathematical calculations in any order, simplifying the analysis enormously, and permitting us to disregard inessential details.
So, although we never actually have a negative number of apples, allowing them to appear in intermediate calculations makes the maths simpler.
The second route is that negative probabilities actually crop up in exactly this way in quantum physics! This isn’t particularly obvious in the standard formulation learned in most undergrad courses, but the theory can also be written in a different way that closely resembles classical statistical mechanics. However, unlike the classical case, the resulting ‘distribution’ is not a normal probability distribution, but a quasiprobability distribution that can also take negative values.
As with Feynman’s apples, these negative values don’t map to anything we observe directly: all measurements we could make give results that occur with zero or positive probabilities, as you would expect. The negative probabilities instead come in as intermediate steps in the calculation.
This should become clearer when I work through a toy example. The particular example I’ll use (which I got from an excellent blog post by Dan Piponi) doesn’t come up in quantum physics, but it’s very close: its main advantage is that the numbers are a bit simpler, so it’s easier to concentrate on the ideas. I’ll do this in two pieces: one that requires no particular physics or maths background and just walks through the example using basic arithmetic, and one that makes connections back to the quantum mechanics literature and might drop in a Pauli matrix or two. This is the no-maths one.
Neither of these routes really get to the point of fully making sense of negative probabilities. In the apple example, we have a tool for making calculations easier, but we also have an interpretation of ‘a negative apple’, in terms of taking away one of the apples you have already. For negative probabilities, we mostly just have the calculational tool. It’s tempting to try and follow the apple analogy and interpret negative probabilities as being to do with something like ‘events unhappening’ – many people have suggested this (see e.g. Michael Nielsen here), and I certainly share the intuition that something like this ought to be possible, but I’ve never seen anything fully worked out along those lines that I’ve found really satisfying.
In the absence of a compelling intuitive explanation, I find it helpful to work through examples and get an idea of how they work. Even if we don’t end up with a good explanation for what negative probabilities are, we can see what they do, and start to build up a better understanding of them that way.
A strange machine
OK, so let’s go through Piponi’s example (here’s the link again). He describes it very clearly and concisely in the post, so it might be a good idea to just switch to reading that first, but for completeness I’ll also reproduce it here.
Piponi asks us to consider a case where:
a machine produces boxes with (ordered) pairs of bits in them, each bit viewable through its own door.
So you could have 0 in both boxes, 0 in the first and 1 in the second, and so on. Now suppose we ask the following three questions about the boxes:
- Is the first box in state 0?
- Is the second box in state 0?
- Are the boxes both in the same state?
I’ll work through two possible sets of answers to these questions: one consistent and unobjectionable set, and one inconsistent and stupid one.
Example 1: consistent answers
Let’s say that we find that the answer to the first question is ‘yes’ , the answer to the second is ‘no’, and the answer to the third is ‘no’. This makes sense, and we can interpret this easily in terms of an underlying state of the two boxes. The first box is in state 0, the second box is in state 1, and so of course the two are in different states and the answer to the third question is also satisfied.
We can represent this situation with the grid below:

The system is in state ‘first box 0, second box 1’, with probability 1, and the other states have probability 0. This is all very obvious – I’m just labouring the point so I can compare it to the case of inconsistent answers, where things get weird.
Example 2: inconsistent answers
Now suppose we find a inconsistent set of answers when we measure the box: ‘no’ to all three questions. This doesn’t make much intuitive sense: both boxes are in state 1, but also they are in different states. Still, Piponi demonstrates that you can still assign something like ‘probabilities’ to the squares on the grid, as long as you’re OK with one of them being negative:

Let’s go through how this matches up with the answers to the questions. For the first question, we have
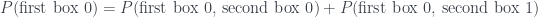

so the answer is ‘no’ as required. Similarly, for the other two questions we have
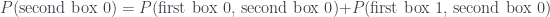

and
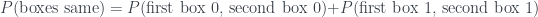

so we get ‘no’ to all three, at the expense of having introduced this weird negative probability in one cell of the grid.
It’s not obvious at all what the negative probability means, though! Piponi doesn’t explain how he came up with this solution, but I’m guessing it’s one of either ‘solve the equations and get the answer’ or ‘notice that these numbers happen to work’.
I wanted to think a bit more about interpretation, and although I haven’t fully succeeded, I did notice a more enlightening calculation method, which maybe points in a useful direction. I’ll describe it below.
A calculation method
Some motivating intuition: all four possible assignments of bits to boxes are inconsistent with the answers in Example 2, but ‘both bits are zero’ is particularly inconsistent. It’s inconsistent with the answers to all three questions, whereas the other assignments are inconsistent with only one question each (for example, ‘both bits are 1’ matches the answer to the first two questions, but is inconsistent with the two states being different).
So you can maybe think in terms of consecutively answering the three questions and penalising assignments that are inconsistent. ‘Both bits are zero’ is an especially bad answer, so it gets clobbered three times instead of just once, pushing the probability negative.
The method I’ll describe is a more formal version of this. I’ll go through it first for Example 1, with consistent answers, to show it works there.
Back to Example 1
Imagine that we start in a state of complete ignorance. We have no idea what the underlying state is, so we just assign probability ¼ to each cell of the grid, like this:

(I’ll stop drawing the axes every time from this point on.) We then ask the three questions in succession and make corrections. For the first question, ‘is the first box in state 0’, we have the answer ‘yes’, so after we learn this we know that the left two cells of the grid now have probability ½ each, and the right two have probability 0. We can think of this as adding a correction term to our previous state of ignorance:

Notice that the correction term has some negative probabilities in it! But these seem relatively benign from an interpretational point of view – they are just removing probability from some cells so that it can be reassigned to others, and the final answer is still positive. It’s kind of similar to saying 
Next, we add on two more correction terms, one for each of the remaining two questions. The correction term for the second question needs to remove probability from the bottom row and add it to the top row, and the one for the third question corrects the diagonals:

Adding ‘em all up gives

So the system is definitely in the top left state, which is what we found before. It’s good to verify that the method works on a conventional example like this, where the final probabilities are positive.
Example 2 again
I’ll follow the same method again for Piponi’s example, starting from complete uncertainty and then adding on a correction for each question (this time the answer is ‘no’ each time). This time I’ll do it all in one go:

which adds up to

So we’ve got the same probabilities as Piponi, with the weird negative -½ probability for ‘both in state 0’. This time we get a little bit more insight into where it comes from: it’s picking up a negative correction term from all three questions.
Discussion
This ‘strange machine’ looks pretty bizarre. But it’s extremely similar to a situation that actually comes up in quantum physics. I’ll go into the details in the follow-up post (‘now with added equations!’), but this example almost replicates the quasiprobability distribution for a qubit, one of the simplest systems in quantum physics. The main difference is that Piponi’s machine is slightly ‘worse’ than quantum physics, in that the -½ value is more negative than anything you get there.
The two examples I did were ones where all three questions have definite yes/no answers, but my method of starting from a state of ignorance and adding on corrections carries over in the obvious way when you have a probability distribution over ‘yes’ and ‘no’. As an example, say you have a 0.8 probability of ‘no’ for the first question. Then you add 0.8 times the correction matrix for ‘no’, with the negative probabilities on the left hand side, and 0.2 times the correction matrix for ‘no’, with the negative probabilities on the right hand side. That’s all there is to it. Just to spell it out I’ll add the general formula: if the three questions have answer ‘no’ with probabilities 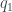

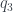

(If you’re wondering where the 
It turns out that all examples in quantum physics are of the type where you don’t have certain knowledge of the answers to all three questions. It’s possible to know the answer to one of them for certain, but then you have to be completely ignorant about the other two, and assign probability ½ to both answers. More usually, you will have partial information about all three questions, with a constraint that the total information you get about the system is at most half the total possible information, in a specific technical sense. To go into this in detail will require some more maths, which I’ll get to in the next post.

3 thoughts on “Negative probability”