Last year I wrote a post which used an obscure term from cognitive psychology and an obscure passage from The Bell Jar to make a confused point about something I didn’t understand very well. I wasn’t expecting this to go very far, but it got more interest than I expected, and some very thoughtful comments. Then John Nerst wrote a much clearer summary of the central idea, attached it to a noisily controversial argument-of-the-month and sent it flying off around the internet. Suddenly ‘cognitive decoupling’ was something of a hit.
If I’d known this was going to happen I might have put a bit more effort into the original blog post. For a start, I might have done some actual reading, instead of just grabbing a term I liked the sound of from one of Sarah Constantin’s blog posts and running with it. So I wanted to understand how the term as we’ve been applying it differs from Stanovich’s original use, and what his influences were. I haven’t done a particularly thorough job on this, but I have turned up a few interesting things, including a surprisingly direct link to a 1987 paper on pretending that a banana is a phone. I also learned that the intellectual history I’d hallucinated for the term based on zero reading was completely wrong, but wrong in a way that’s been strangely productive to think about. I’ll describe both the actual history and my weird fake one below. But first I’ll briefly go back over what the hell ‘cognitive decoupling’ is supposed to mean, for people who don’t want to wade through all those links.
Roses, tripe, and the bat and ball again
Stanovich is interested in whether, to use Constantin’s phrase, ‘rational people exist’. In this case ‘rational’ behaviour is meant to mean something like systematically avoiding cognitive biases that most people fall into. One of his examples is the Wason selection task, which involves turning over cards to verify the statement ‘If the card has an even number on one face it will be red on the reverse’. More vivid real-world situations, like Stanovich’s example of ‘if you eat tripe you will get sick’, are much easier for people to reason about than the decontextualised card-picking version. (Cosmides and Tooby’s beer version is even easier than the tripe one.)
A second example he gives is the ‘rose syllogism’:
Premise 1: All living things need water
Premise 2: Roses need water
Therefore, Roses are living things
A majority of university students incorrectly judge this as valid, whereas almost nobody thinks this structurally equivalent version makes sense:
Premise 1: All insects need oxygen
Premise 2: Mice need oxygen
Therefore, Mice are insects
The rose conclusion fits well with our existing background understanding of the world, so we are inclined to accept it. The mouse conclusion is stupid, so this doesn’t happen.
A final example would be the bat and ball problem from the Cognitive Reflection Test: ‘A bat and a ball cost $1.10. The bat costs $1 more than the ball. How much does the ball cost?’. I’ve already written about that one in excruciating detail, so I won’t repeat myself too much, but in this case the interfering context isn’t so much background knowledge as a very distracting wrong answer.
Stanovich’s contention is that people that manage to navigate these problems successfully have an unusually high capacity for something he calls ‘cognitive decoupling’: separating out the knowledge we need to reason about a specific situation from other, interfering contextual information. In a 2013 paper with Toplak he describes decoupling as follows:
When we reason hypothetically, we create temporary models of the world and test out actions (or alternative causes) in that simulated world. In order to reason hypothetically we must, however, have one critical cognitive capability—we must be able to prevent our representations of the real world from becoming confused with representations of imaginary situations. The so-called cognitive decoupling operations are the central feature of Type 2 processing that make this possible…
The important issue for our purposes is that decoupling secondary representations from the world and then maintaining the decoupling while simulation is carried out is the defining feature of Type 2 processing.
(‘Type 2’ is a more recent name for ‘System 2’, in the ‘System 1’/’System 2’ dual process typology made famous by Kahneman’s Thinking, Fast and Slow. See Kaj Sotala’s post here for a nice discussion of Stanovich and Evan’s work relating this split to the idea of cognitive decoupling, and other work that has questioned the relevance of this split.)
I don’t know how well this works as an explanation of what’s really going on in these situations. I haven’t dug into the history of the Wason or rose-syllogism tests at all, and, as with the bat and ball question, I’d really like to know what was done to validate these as good tests. What similar questions were tried? What other explanations, like prior exposure to logical reasoning, were identified, and how were these controlled for? I don’t have time for that currently. For the purposes of this post, I’m more interested in understanding what Stanovich’s influences were in coming up with this idea, rather than whether it’s a particularly good explanation.
Context, wide and narrow
Constantin’s post is more or less what she calls a ‘fact post’, summarising research in the area without too much editorial gloss. When I picked this up, I was mostly excited by the one bit of speculation at the end, and the striking ‘cognitive decoupling elite’ phrase, and didn’t make any effort to stay close to Stanovich’s meaning. Now I’ve read some more, I think that in the end we didn’t drift too far away. Here is Nerst’s summary of the idea:
High-decouplers isolate ideas from each other and the surrounding context. This is a necessary practice in science which works by isolating variables, teasing out causality and formalizing and operationalizing claims into carefully delineated hypotheses. Cognitive decoupling is what scientists do.
To a high-decoupler, all you need to do to isolate an idea from its context or implications is to say so: “by X I don’t mean Y”. When that magical ritual has been performed you have the right to have your claims evaluated in isolation. This is Rational Style debate…
While science and engineering disciplines (and analytic philosophy) are populated by people with a knack for decoupling who learn to take this norm for granted, other intellectual disciplines are not. Instead they’re largely composed of what’s opposite the scientist in the gallery of brainy archetypes: the literary or artistic intellectual.
This crowd doesn’t live in a world where decoupling is standard practice. On the contrary, coupling is what makes what they do work. Novelists, poets, artists and other storytellers like journalists, politicians and PR people rely on thick, rich and ambiguous meanings, associations, implications and allusions to evoke feelings, impressions and ideas in their audience. The words “artistic” and “literary” refers to using idea couplings well to subtly and indirectly push the audience’s meaning-buttons.
Now of course, Nerst is aiming at a much wider scope – he’s trying to apply this to controversial real-world arguments, rather than experimental studies of cognitive biases. But he’s talking about roughly the same mechanism of isolating an idea from its surrounding context.
There is a more subtle difference, though, that I find interesting. It’s not a sharp distinction so much as a difference in emphasis. In Nerst’s description, we’re looking at the coupling between one specific idea and its whole background context, which can be a complex soup of ‘thick, rich and ambiguous meanings, associations, implications and allusions’. This is a clear ‘outside’ description of the beautiful ‘inside’ one that I pulled from The Bell Jar, talking about how it actually feels (to some of us, anyway) to drag ideas out from the context that gave them meaning:
Botany was fine, because I loved cutting up leaves and putting them under the microscope and drawing diagrams of bread mould and the odd, heart-shaped leaf in the sex cycle of the fern, it seemed so real to me.
The day I went in to physics class it was death.
A short dark man with a high, lisping voice, named Mr Manzi, stood in front of the class in a tight blue suit holding a little wooden ball. He put the ball on a steep grooved slide and let it run down to the bottom. Then he started talking about let a equal acceleration and let t equal time and suddenly he was scribbling letters and numbers and equals signs all over the blackboard and my mind went dead.
… I may have made a straight A in physics, but I was panic-struck. Physics made me sick the whole time I learned it. What I couldn’t stand was this shrinking everything into letters and numbers. Instead of leaf shapes and enlarged diagrams of the hole the leaves breathe through and fascinating words like carotene and xanthophyll on the blackboard, there were these hideous, cramped, scorpion-lettered formulas in Mr Manzi’s special red chalk.
In this description, the satisfying thing about the botany classes is the rich sensory context: the sounds of the words, the vivid images of ferns and bread mould, the tactile sense of chopping leaves. This is a very broad-spectrum idea of context.
Now, Stanovich does seem to want cognitive decoupling to apply in situations where people access a wide range of background knowledge (‘roses are living things’), but when he comes to hypothesising a mechanism for how this works he goes for something with a much narrower focus. In the 2013 paper with Toplak he talks about specific, explicit ‘representations’ of knowledge interfering with other explicit representations. (I’ll go into more detail later about exactly what he means by a ‘representation’.) He cites an older paper, Pretense and Representation by Leslie, as inspiration for the ‘decoupling’ term:
In a much-cited article, Leslie (1987) modeled pretense by positing a so-called secondary representation (see Perner 1991) that was a copy of the primary representation but that was decoupled from the world so that it could be manipulated — that is, be a mechanism for simulation.
This is very clearly about being able to decouple one specific explicit belief from another similarly explicit ‘secondary representation’, rather than the whole background morass of implicit context. I wanted to understand how this was supposed to work, so I went back and read the paper. This is where the banana phones come in.
Pretending a banana is a phone
The first surprise for me was how literal this paper was. (Apparently 80s cognitive science was like that.) Leslie is interested in how pretending works – how a small child pretends that a banana is a telephone, to take his main example. And the mechanism he posits is… copy-and-paste, but for the brain:
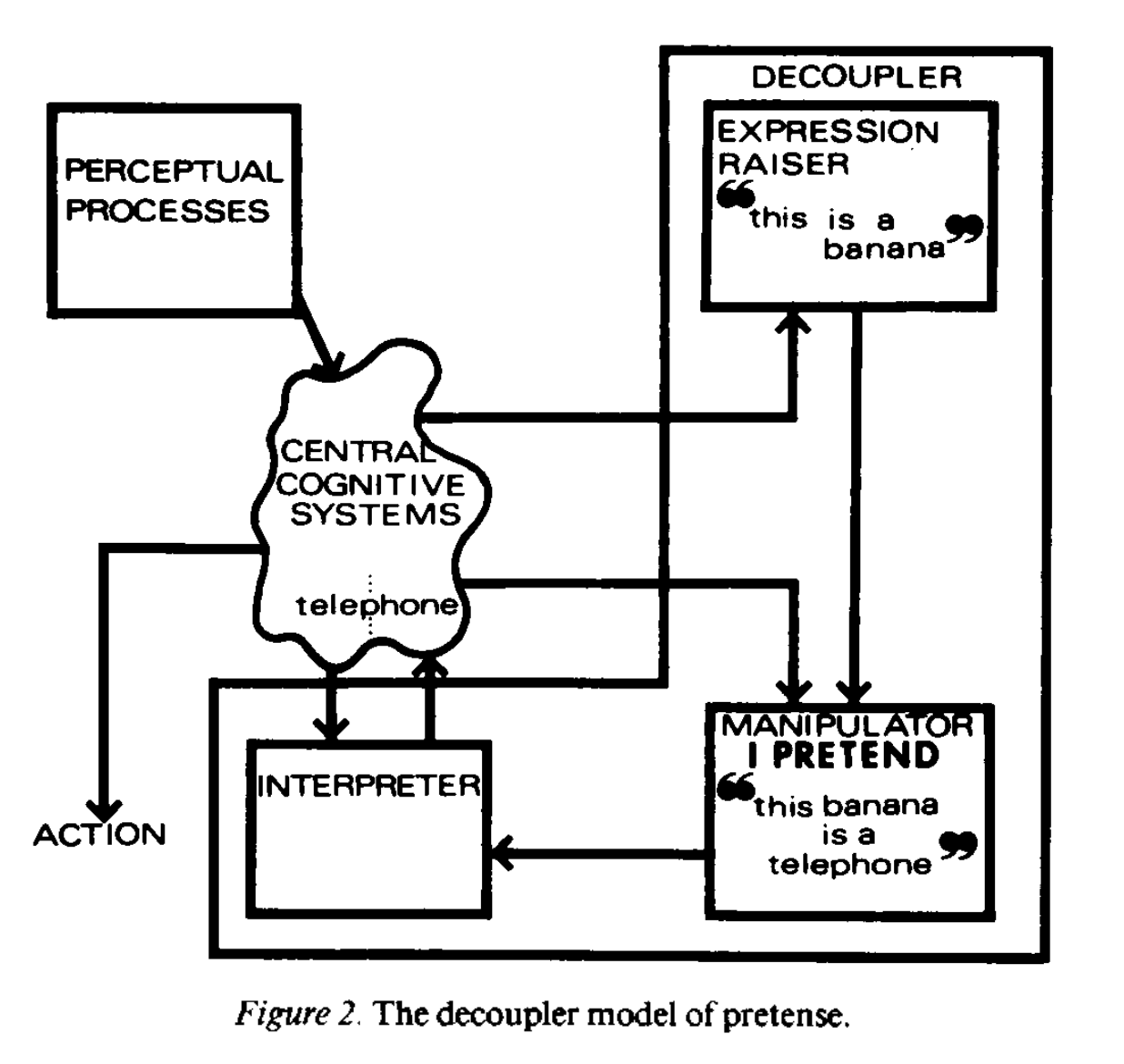
As in, we get some kind of perceptual input which causes us to store a ‘representation’ that means ‘this is a banana’. Then we make a copy of this. Now we can operate on the copy (‘this banana is a telephone’) without also messing up the banana representation. They’ve become decoupled.
What are these ‘representations’? Leslie has this to say:
What I mean by representation will, I hope, become clear as the discussion progresses. It has much in common with the concepts developed by the information-processing, or cognitivist, approach to cognition and perception…
This is followed by a long string of references to Chomsky, Dennett, etc. So his main influence appears to be, roughly, computational theories of mind. Looking at how he uses the term in the paper itself, it appears that we’re in the domain of Good Old-Fashioned AI: ‘representations’ can be put into a rough correspondence with English propositions about bananas, telephones, and cups of tea, and that we then use them as a kind of raw material to run inference rules on and come to new conclusions:

Leslie doesn’t talk about how all these representations come to mean anything in the real world — how do we know that the string of characters ‘cups contain water’, or its postulated mental equivalent, has anything to do with actual cups and actual water? How do we even parse the complicated flux of the real world into discrete named objects, like ‘cups’, to start with? There’s no story in the paper that tries to bridge this gap — these representations are just sitting there ‘in the head’, causally disconnected from the world.
Well, OK, maybe 80s cognitive science was like that. Maybe Leslie thought that someone else already had a convincing story for how this bit works, and he could just apply the resulting formalism of propositions and inference rules. But this same language of ‘representations’ and ‘simulations’ is still being used uncritically in much more recent papers. Stanovich and Toplak, for example, reproduce Leslie’s decoupling diagram and describe it using the same terms:
For Leslie (1987), the decoupled secondary representation is necessary in order to avoid representational abuse — the possibility of confusing our simulations with our primary representations of the world as it actually is… decoupled representations of actions about to be taken become representations of potential actions, but the latter must not infect the former while the mental simulation is being carried out.
There’s another strange thing about Stanovich using this paper as a model to build on. (I completely missed this, but David Chapman pointed it out to me in an earlier conversation.) Stanovich is interested in what makes actions or behaviours rational, and he wants cognitive decoupling to be at least a partial explanation of this. Leslie is looking at toddlers pretending that bananas are telephones. If even very young children are passing this test for ‘rationality’, it’s not going to be much use for discriminating between ‘rational’ and ‘irrational’ behaviour in adults. So Stanovich would need a narrower definition of ‘decoupling’ that excludes the banana-telephone example if he wants to eventually use it as a rationality criterion.
So I wasn’t very impressed with this as a plausible mechanism for decoupling. Then again, the mechanism I’d been imagining turns out to have some obvious failings too.
Rabbits and the St. Louis Arch
When I first started thinking about cognitive decoupling, I imagined a very different history for the term. ‘Decoupling’ sounds very physicsy to me, bringing up associations of actual interaction forces and coupling constants, and I’d been reading Dreyfus’s Why Heideggerian AI Failed, which discusses dynamical-systems-inspired models of cognition:
Fortunately, there is at least one model of how the brain could provide the causal basis for the intentional arc. Walter Freeman, a founding figure in neuroscience and the first to take seriously the idea of the brain as a nonlinear dynamical system, has worked out an account of how the brain of an active animal can find and augment significance in its world. On the basis of years of work on olfaction, vision, touch, and hearing in alert and moving rabbits, Freeman proposes a model of rabbit learning based on the coupling of the brain and the environment…
The organism normally actively seeks to improve its current situation. Thus, according to Freeman’s model, when hungry, frightened, disoriented, etc., the rabbit sniffs around until it falls upon food, a hiding place, or whatever else it senses it needs. The animal’s neural connections are then strengthened to the extent that reflects the extent to which the result satisfied the animal’s current need. In Freeman’s neurodynamic model, the input to the rabbit’s olfactory bulb modifies the bulb’s neuron connections according to the Hebbian rule that neurons that fire together wire together.
In many ways this still sounds like a much more promising starting point to me than the inference-rule-following of the Leslie paper. For a start, it seems to fit much better with what’s known about the architecture of the brain (I think – I’m pretty ignorant about this). Neurons are very slow compared to computer processors, but make up for this by being very densely interconnected. So getting anything useful done would rely on a huge amount of activation happening in parallel, producing a kind of global, diffuse ‘background context’ that isn’t sharply divided into separate concepts.
Better still, the problem of how situations intrinsically mean something about the world is sidestepped, because in this case, the rabbit and environment are literally, physically coupled together. A carrot smell out in the world pulls its olfactory bulb into a different state, which itself pulls the rabbit into a different kind of behaviour, which in turn alters the global structure of the bulb in such a way that this behaviour is more likely to occur again in the future. This coupling is so direct that referring to it as a ‘representation’ seems like overkill:
Freeman argues that each new attractor does not represent, say, a carrot, or the smell of carrot, or even what to do with a carrot. Rather, the brain’s current state is the result of the sum of the animal’s past experiences with carrots, and this state is directly coupled with or resonates to the affordance offered by the current carrot.
However, this is also where the problems come in. Everything is so closely causally coupled that there’s no room in this model for decoupling! The idea behind ‘cognitive decoupling’ is to be able to pull away from the world long enough to consider things in the abstract, without all the associations that normally get dragged along for free. In the olfactory bulb model, the rabbit is so locked into its surroundings that this sort of distance is unattainable.
At some point I was googling a bunch of keywords like ‘dynamical systems’ and ‘decoupling’ in the hope of fishing up something interesting, and I came across a review by Rick Grush of Mind as Motion: Explorations in the Dynamics of Cognition by Port and van Gelder, which had a memorable description of the problem:
…many paradigmatically cognitive capacities seem to have nothing at all to do with being in a tightly coupled relationship with the environment. I can think about the St. Louis Arch while I’m sitting in a hot tub in southern California or while flying over the Atlantic Ocean.
Even this basic kind of decoupling from a situation – thinking about something that’s not happening to you right now – needs some capacities that are missing from the olfactory bulb model. Grush even uses the word ‘decoupling’ to describe this:
…what is needed, in slightly more refined terms, is an executive part, C (for Controller), of an agent, A, which is in an environment E, decoupling from E, and coupling instead to some other system E’ that stands in for E, in order for the agent to ‘think about’ E (see Figure 2). Cognitive agents are exactly those which can selectively couple to either the ‘real’ environment, or to an environment model, or emulator, perhaps internally supported, in order to reason about what would happen if certain actions were undertaken with the real environment.
This actually sounds like a plausible alternate history for Stanovich’s idea, with its intellectual roots in dynamical systems rather than the representational theory of mind. So maybe my hallucinations were not too silly after all.
Final thoughts
I still think that the idea of cognitive decoupling is getting at something genuinely interesting – otherwise I wouldn’t have spent all this time rambling on about it! I don’t think the current representational story for how it works is much good. But the ability to isolate ‘abstract structure’ (whatever that means, exactly) from its surrounding context does seem to be a real skill that people vary in. In practice I expect that much of this context will be more of a diffuse associational soup than the sharp propositional statements of Leslie’s pretence model.
It’s interesting to me that the banana phone model and the olfactory bulb model both run into problems, but in opposite directions. Leslie’s banana phone relies on a bunch of free-floating propositions (‘this is a banana’), with no story for how they refer to actual bananas and phones out in the world. Freeman’s rabbit olfactory bulb has no problem with this – relevance is guaranteed through direct causal coupling to the outside world – but it’s so directly coupled that there’s no space for decoupling. We need something between these two extremes.
David Chapman pointed out to me that Brian Cantwell Smith already has a term for this in The Origin of Objects – he calls it ‘the middle distance’ between direct coupling and causal irrelevance. I’ve been reading the book and have already found his examples to be hugely useful in thinking about this more clearly. These are worth a post in their own right, so I’ll describe them in a followup to this one.


 starting from the binomial expansion as one example. He takes
starting from the binomial expansion as one example. He takes  as infinitely small and
as infinitely small and  as infinitely large, and is happy to assume their product is finite without worrying too much. “The modern reader may be left slightly breathless”, but he gets the right answer.
as infinitely large, and is happy to assume their product is finite without worrying too much. “The modern reader may be left slightly breathless”, but he gets the right answer.

 to things, instead of
to things, instead of  . Why? No idea! It’s not like
. Why? No idea! It’s not like 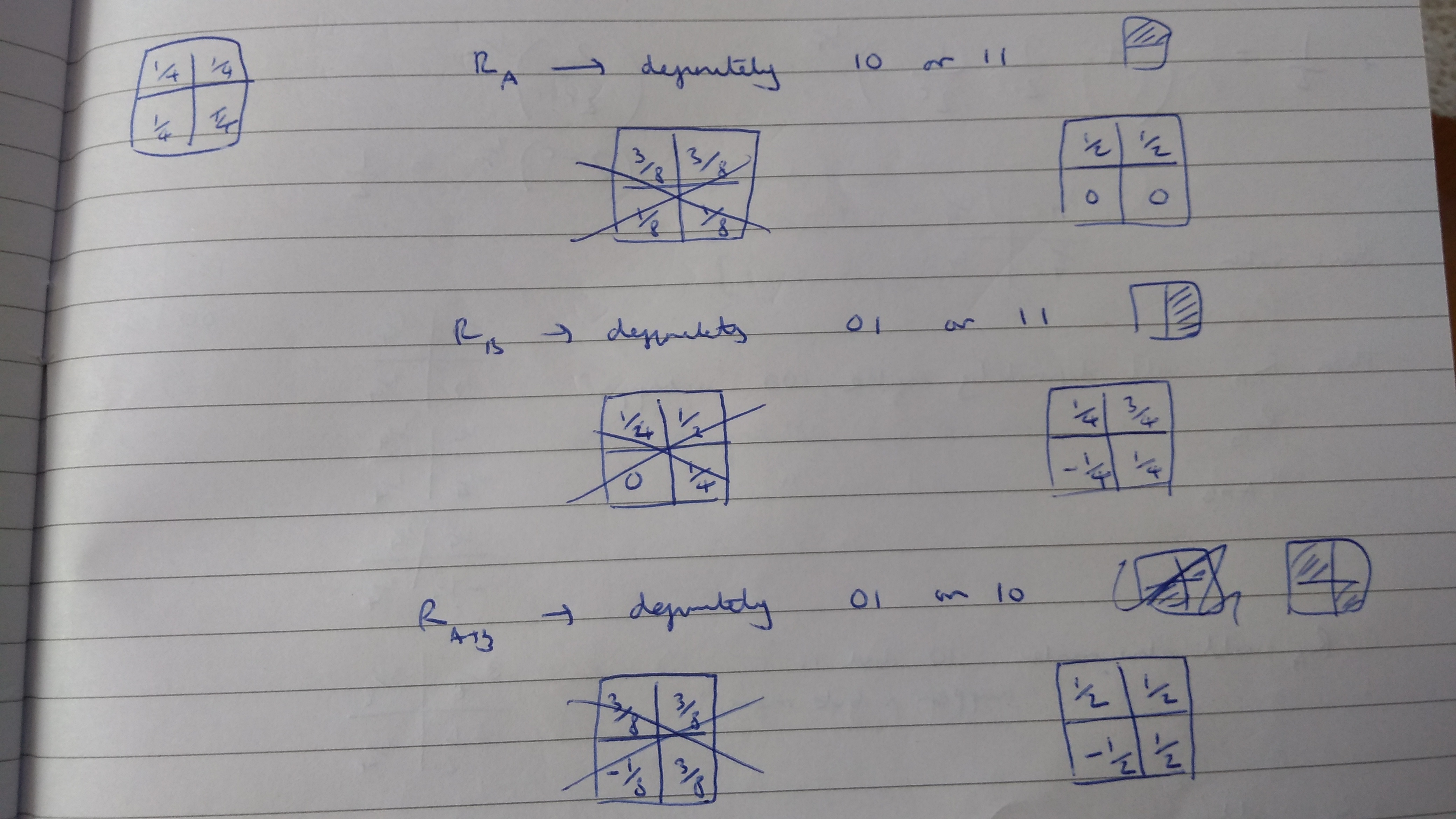

 state. The three questions then become measurements on it. Specifically, these measurements are expectation values
state. The three questions then become measurements on it. Specifically, these measurements are expectation values  of the operators
of the operators 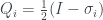 , where the
, where the  are the three Pauli matrices.
are the three Pauli matrices.

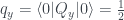
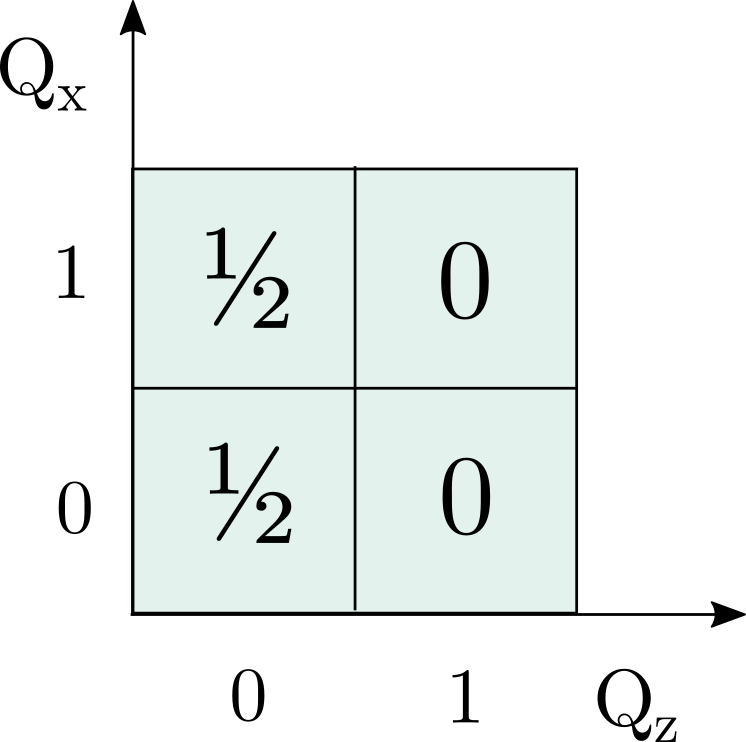
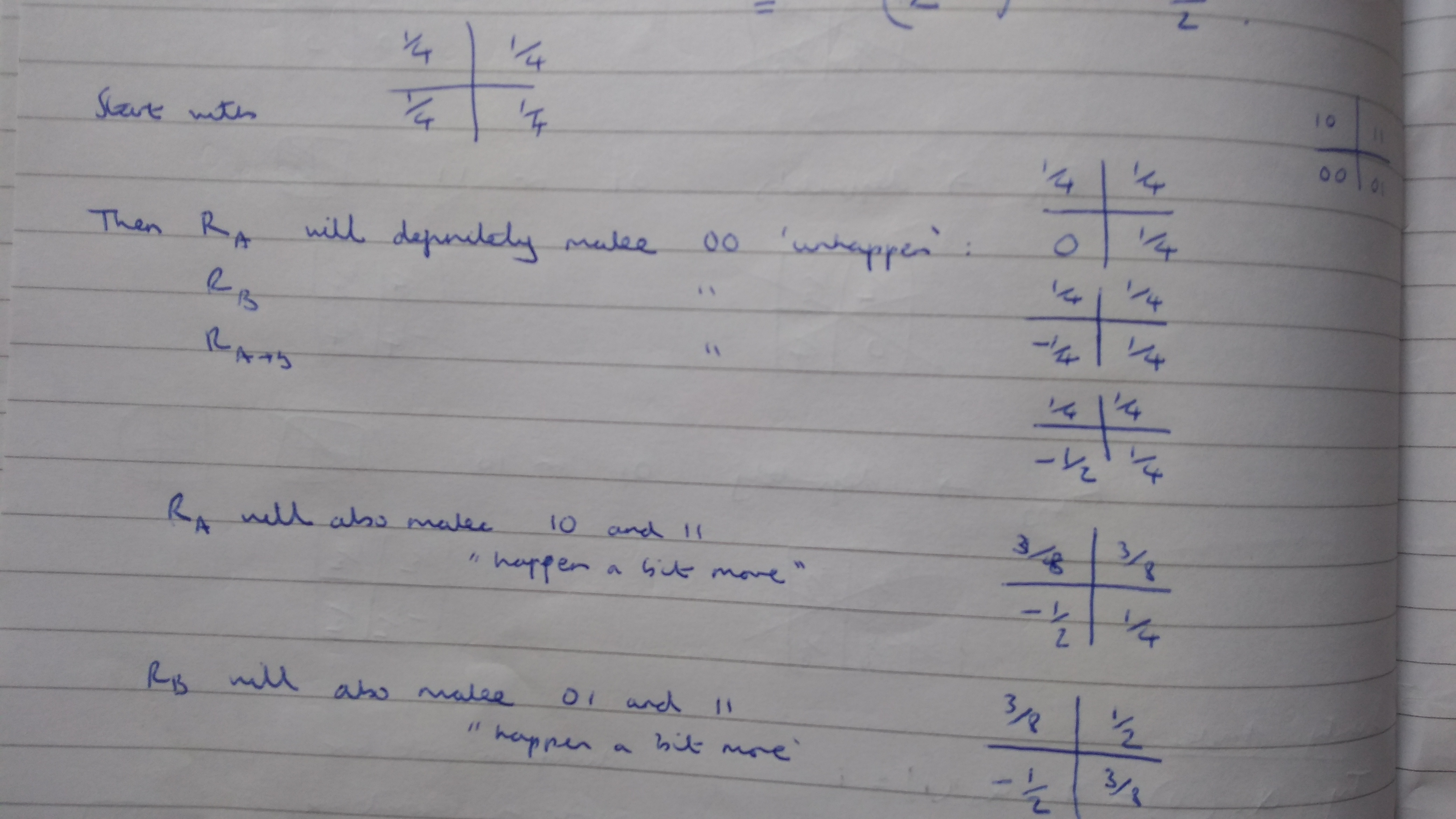
 measurement, so the probabilities in the cells where
measurement, so the probabilities in the cells where  must sum to 1. For the
must sum to 1. For the  state there is an equal chance of either
state there is an equal chance of either  or
or  . The third measurement,
. The third measurement, 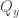 , can be shown to be associated with the diagonals of the grid, in the same way as in Piponi’s example in the previous post, and again there is an equal chance of either value. Imposing all these conditions gives the probability assignment above.
, can be shown to be associated with the diagonals of the grid, in the same way as in Piponi’s example in the previous post, and again there is an equal chance of either value. Imposing all these conditions gives the probability assignment above. 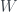 . To save on drawing diagrams, I’ll represent this as a square-bracketed matrix from now on:
. To save on drawing diagrams, I’ll represent this as a square-bracketed matrix from now on: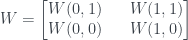
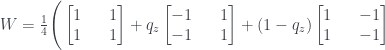
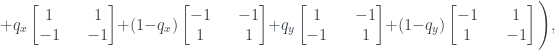
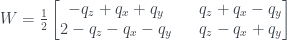
 . (This is the +1 eigenvector of the density matrix
. (This is the +1 eigenvector of the density matrix 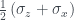 .)
.)  is
is 
 state has no magic – all the values are nonnegative. This also holds for the other five, which have the following Wigner functions:
state has no magic – all the values are nonnegative. This also holds for the other five, which have the following Wigner functions: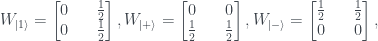
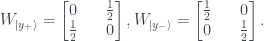
 as before? Well, I briefly mentioned the reason in the previous blog post, but I can go into more detail now. There are constraints on the values of
as before? Well, I briefly mentioned the reason in the previous blog post, but I can go into more detail now. There are constraints on the values of  of what half the knowledge means. He stipulates that this measure should have
of what half the knowledge means. He stipulates that this measure should have  for the six half-the-knowledge states we already have, which seems reasonable. Also, it should have
for the six half-the-knowledge states we already have, which seems reasonable. Also, it should have 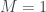 for states where we know all the information (impossible in quantum physics), and
for states where we know all the information (impossible in quantum physics), and  for the state of total ignorance about all questions. Or to put it a bit differently,
for the state of total ignorance about all questions. Or to put it a bit differently,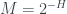 ,
, is an entropy measure – it decreases from 2 to 1 to 0 as we learn more information about the system. There’s a parametrised family
is an entropy measure – it decreases from 2 to 1 to 0 as we learn more information about the system. There’s a parametrised family  of entropies known as the
of entropies known as the 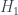 , used widely in information theory, but it turns out that this one doesn’t reproduce the states found in quantum physics. Instead, van Enk picks
, used widely in information theory, but it turns out that this one doesn’t reproduce the states found in quantum physics. Instead, van Enk picks 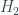 , the collision entropy. This has quite a simple form:
, the collision entropy. This has quite a simple form: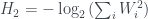 ,
,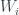 are the four components of
are the four components of  , and the second constraint on
, and the second constraint on  :
: .
.

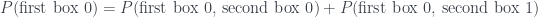

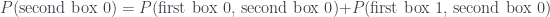

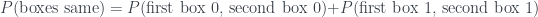



 , where we subtract some probability to get to the answer.
, where we subtract some probability to get to the answer. 



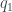 ,
,  ,
, 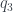 respectively, then we assign probabilities to the cells as follows:
respectively, then we assign probabilities to the cells as follows:

{kind=link}